PlatON


近日,PlatON在网站发布了白皮书2.0版,新版白皮书在此前初版的基础上,广纳全球社区开发者、技术爱好者的建议,并对部分细节进行了重新修订。
PlatON2.0是PlatON下一阶段的重要战略部署,将通过建立去中心化的隐私计算网络,形成去中心化的人工智能市场,从而实现自组织协作的通用人工智能网络。为使用户全面了解PlatON2.0,打开通往通用人工智能的道路,寻找技术关键之钥,PlatON将开启白皮书解读专题。
本文由PlatON社区爱好者IdyII撰写
白皮书获取链接:
| 前言
PlatON主网于今年4月30日正式上线,上线以来我们清晰地看到正如路线图所展现的一个高TPS、去中心化、具备EVM、WASM双虚拟机的高性能去中心化网络。
在之前的白皮书1.0中,PlatON想要实现的最终愿景,正是下一代的高性能、可扩容、支持隐私保护的去中心云计算服务网络。按照规划路线图,进而将隐私网络分为3层。
第一层-去中心化网络层,具备完整的图灵完备虚拟机。
第二层-隐私计算层,具备可信环境下的隐私安全计算网络。
第三层-自治网络层,具备独立的自主训练模型。
从目前的进展来看,解读到的是这三个关键词:去中心化、合规、隐私计算。在数据爆炸的时代,隐私至关重要,然而想要完成真正的隐私计算,合规、去中心化缺一不可。而这两项几乎在主网上线之日全部展现,并公布了精心设计的经济模型和治理机制,以及关于LAT的发行和通胀周期都一一展现,说明在合规这条路上PlatON是认真的。
去中心化节点则在PlatON元网络Alaya的基础上做了更高的扩展性。基于自研的高性能Giskard共识协议的出块共识,在共识层更好地完成去中心化的任务。这是我们在PlatON主网上线后所看到的一个落地场景。
而如今PlatON白皮书2.0的发布,我们可以进一步看到,PlatON在隐私计算层跨出了更大一步。据白皮书所述,将隐私计算层分为两个网络:隐私计算网络、隐私AI服务平台以及Layer3-AI代理自治网络。PlatON2.0所要解决的问题正是高性能的计算节点和低成本训练的隐私计算部分。
笔者理解这正是Web2.0迈向3.0的关键一步。真正将区块链应用落地,而又能产生价值的必然结果。但也同时要保持审慎的态度,包括像去中心化存储板块,也依然存在很大的技术挑战。
| 隐私计算之路的关键技术
理解PlatON2.0之前,我们不得不提到隐私计算技术之路上的关键技术:
可信执行环境(TEE)
目前机密计算的成熟技术有TrustZone和Intel SGX两类,主流的机密计算开源框架大多是基于IntelSGX。
2013年,Intel公司提出了新的处理器安全技术SGX,能够在计算平台上提供一个可信的隔离空间,保障用户关键代码和数据的机密性和完整性。Intel SGX是Intel架构新的扩展,在原有架构上增加了一组新的指令集和内存访问机制。
这些扩展允许应用程序实现一个被称为enclave的容器,在应用程序的地址空间中划分出一块被保护的区域,为容器内的代码和数据提供机密性和完整性的保护,免受拥有特殊权限的恶意软件的破坏。
Enclave则是一个被保护的内容容器,用于存放应用程序敏感数据和代码。SGX允许应用程序指定需要保护的代码和数据部分,在创建enclave之前,不必对这些代码和数据进行检查或分析,但加载到enclave中去的代码和数据必须被度量。当应用程序需要保护的部分加载到enclave后,SGX保护它们不被外部软件所访问。
Enclave可以向远程认证者证明自己的身份,并提供必需的功能结构用于安全地提供密钥。用户也可以请求独有的密钥,这个密钥通过结合enclave身份和平台的身份做到独一无二,可以用来保护存储在enclave之外的密钥或数据。
如果上面的描述太复杂,你可以这样简单理解:TEE将系统的软硬件资源划分成两个执行环境——安全环境和普通环境。而前者就像是美剧里常说的“安全屋”(safe house),拥有更高的执行权限,普通环境无法对其进行访问,对里面的情况更是无从知晓。
联邦学习
联邦学习本质上是一种分布式机器学习技术,或机器学习架。目标是在保证数据隐私安全及合法合规的基础上,实现共同建模,提升AI模型的效果。联邦学习分为横向联邦学习、纵向联邦学习、联邦迁移学习三类,通过加密机制下的参数交换方式保护用户数据隐私,加密手段包括同态加密、半同态加密等。
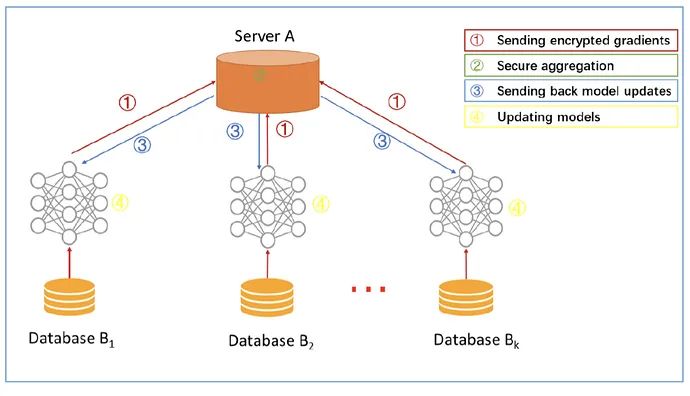
简单介绍横向联邦学习系统的典型架构,如图所示。在该系统中,具有相同数据结构的k个参与者通过参数或云服务器协同学习机器学习模型。一个典型的假设是参与者是诚实的,而服务器是诚实但好奇的,因此不允许任何参与者向服务器泄漏信息。这种系统的训练过程通常包括以下四个步骤:
- 第一步:参与者在本地计算训练梯度,使用加密、差异隐私或秘密共享技术掩饰所选梯度,并将掩码后的结果发送到服务器;
- 第二步:服务器执行安全聚合,不了解任何参与者的信息;
- 第三步:服务器将汇总后的结果发送给参与者;
- 第四步:参与者用解密的梯度更新他们各自的模型。
通过上述步骤进行迭代,直到损失函数收敛,从而完成整个训练过程。该结构独立于特定的机器学习算法(逻辑回归、DNN等),所有参与者将共享最终的模型参数。
横向联邦学习乍一看有点类似于分布式机器学习。分布式机器学习包括训练数据的分布式存储、计算任务的分布式操作、模型结果的分布式分布等多个方面,参数服务器是分布式机器学习中的一个典型元素。作为加速训练过程的工具,参数服务器将数据存储在分布式工作节点上,通过中央调度节点分配数据和计算资源,从而更有效地训练模型。
对于横向联邦学习,工作节点表示数据所有者。它对本地数据具有完全的自主性,可以决定何时以及如何加入联邦学习。在参数服务器中,中心节点始终处于控制状态,因此联邦学习面临着一个更加复杂的学习环境。
其次,联邦学习强调在模型训练过程中数据所有者的数据进行隐私保护。数据隐私保护的有效措施可以更好地应对未来日益严格的数据隐私和数据安全监管环境。
因此,在此基础上引入可信执行环境和去中心化的区块链网络,还有安全多方计算和零知识证明等区块链领域很成熟的主流密码学技术,即可完成隐私计算完整的一块拼图。
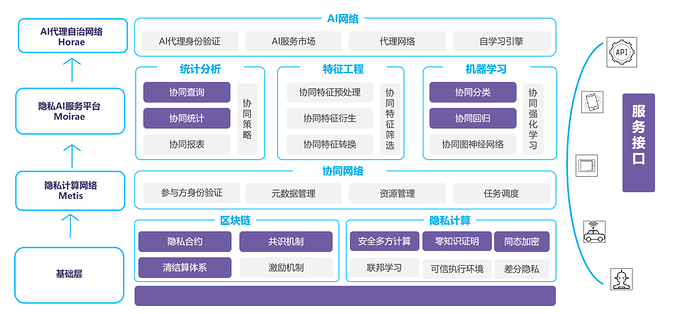
PlatON技术整体架构
区块链层也就是所谓的基础层提供面向机器的接口,这些接口可以提供计算的Token激励、清算以及制定相关的隐私合约。在隐私计算层,部分机器作为计算节点在隐私计算网络或隐私AI服务平台主要依托同态加密和零知识证明提供隐私外包训练、安全多方计算等操作。
前两种技术路径主要是在软件和算法层面实现隐私计算,而可信执行环境则取决于对安全硬件的信赖。比如,隐私外包训练更适合数据挖掘,满足复杂的建模计算;安全多方计算通用性强、安全性高,同时对算力等使用要求高。在AI代理自助网络层将AI学习门槛降到最低,以至于人人可以参与训练。因此,从技术架构的角度来讲PlatON实现的是:联邦计算+安全多方计算+安全的可执行环境+区块链激励机制的一个隐私计算网络。
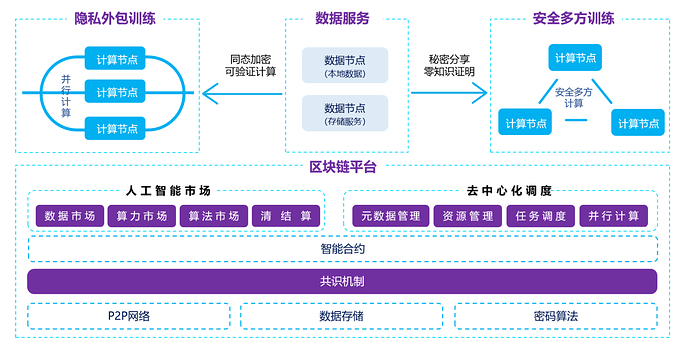
隐私计算网络以去中心化方式聚集计算所需的数据、算法和算力,创造安全的隐私计算范式。
隐私AI服务平台实现去中心化的人工智能“云”平台,一方面面向开发者提供一站式AI开发平台,提供一站式全方位的建模流程,帮助用户快速创建和部署模型,管理全周期AI工作流;另一方面也是一个开放人工智能市场,开发人员可以在网络上找到训练数据集训练模型,推出人工智能模型,可以与其他人工智能模型和付费用户进行交互。
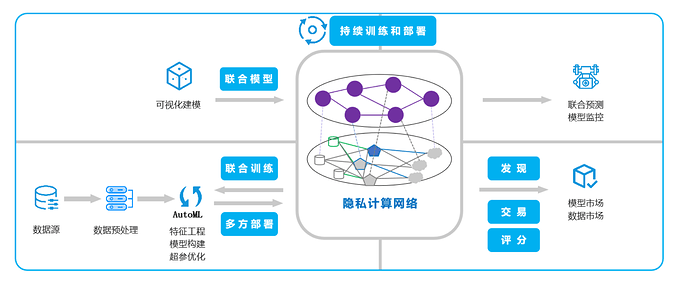
AI代理自治网络
对于想通过网络提供人工智能服务的开发者来说,最关键的组件是服务节点,它是一个AI模型的执行容器,可托管多个AI模型并对外提供AI服务。考虑到网络冗余和容错,AI模型一般可托管到多个服务节点,并且可以在服务节点间迁移。
注册节点和评估节点构成智能搜索网络,进行AI服务和代理的搜索和交互。AI服务和代理将其文本描述和标签登记到注册节点,以便用户发现它们的服务、定价、地址等信息,并调用它们。评估节点对AI服务和代理进行服务测试、评估和评级,通过共识算法建立一个信誉评分系统,并以此为依据进行搜索和推荐,使得其他用户能够迅速和容易地查询AI服务和代理。评估的效果可以通过基于历史数据训练的机器学习算法来提高,比如成功的查询和交互。使用基于机器学习的搜索,用户能够识别潜在的AI服务和代理。
AI代理自治网络旨在利用自组织的群体智能来创造一个大于其各部分之和的整体。自主代理不仅仅是存在于数字世界,也可以作为数字世界与真实世界的桥梁,连接到人类、IoT设备和外部IT系统。每个自主代理是独立运行的守护进程,各自追求自己相对简单的目标,但在它们的互动中将产生更复杂的目标,生成更智能的高阶代理。
对于元宇宙来讲,最大的特点是,将虚拟世界和现实世界互通。以至于可以将虚拟世界的资产映射到现实生活中来满足日常需求,私有虚拟作品的交易、基于隐私的游戏智能体训练、对真实数据的挖掘等等这些,都需要一种安全放心的技术或机制来完成,这就需要像PlatON AI代理自治网络这样的技术和平台。
再以生物医药为例,预计这将大大受益于隐私计算技术的兴起。疾病症状、基因序列、医学报告等医学数据是非常敏感和私密的,然而医学数据很难收集,它们存在于孤立的医疗中心和医院中。数据源的不足和标签的缺乏导致机器学习模型的性能不理想,成为当前智慧医疗的瓶颈。我们设想,如果所有的医疗机构都联合起来,共享他们的数据,形成一个大型的医疗数据集,那么在该大型医疗数据集上训练的机器学习模型的性能将显著提高。
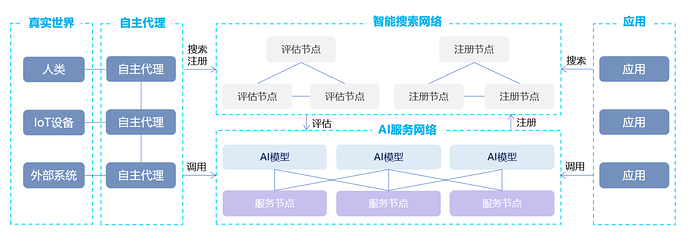
通过PlatON2.0技术的整体架构,最直观的感受便是,一个应用场景巨大,并且技术实现难度极高的一个隐私计算网络,而在技术细节中笔者认为,这四层网络能够有效地结合并发挥出其自身的作用,需要一个难度极高的技术方案。对于PlatON来讲不仅是一项技术,而是一种未来的商业模式。
近年来,数据的隔离和对数据隐私的强调正成为人工智能的下一个挑战,但是隐私计算网络给我们带来了新的希望。它可以在保护本地数据的同时,为多个企业建立一个统一的模型,使企业在以数据安全为前提的情况下取得双赢。
预计在不久的将来,隐私计算网络将打破行业之间的障碍,建立一个可以与安全共享数据和知识的社区,并根据每个参与者的贡献公平分配利益。自此,可以让每一个社区贡献者参与其中。
参考文献:
[1] https://devdocs.platon.network/docs/zh-CN/
[2] Wang J, Fan CY, Cheng YQ, Zhao B, Wei T, Yan F, Zhang HG, Ma J. Analysis and Research on SGX Technology. Journal of Software, 2018, 29(9): 2778-2798(in Chinese).http://www.jos.org.cn/1000-9825/5594.htm
[3] Qiang Yang, Yang Liu, Tianjian Chen, and Yongxin Tong. 2019. Federated Machine Learning: Concept and Applications. ACM Trans. Intell. Syst. Technol. 10, 2, Article 12 (February 2019), 19 pages. https://doi.org/0000001.0000001
本文转载自https://mp.weixin.qq.com/s/2f34sQuxNKNM_XfyFZaHCg



