Author:30+
The following content is my personal opinion, it does not represent any investment advice.
If you appreciate it, please like, comment, and share!


PlatON 2.0 White Paper: Decentralized Privacy-Preserving AI Networ white paper was released, in which data utilization, privacy computing, AI and other fields have been mentioned many times. This article will combine part of the content of the white paper to interpret the content of the white paper in terms of data protection, flow, and value realization.
In just the past 10 years society has witnessed the transition of analog to digital, and we are fast forward to a fully digital life. However, the data utilization rate is very low due to the high centralization of artificial intelligence, coupled with data abuse and privacy leakage. The value of data urgently needs to be intellectualized in order to be deposited and utilized, hence the growing call for a next-generation intelligent network known as web 3.0.
Data development trend
According to Statista analysis[1], the number of connected devices worldwide is expected to reach 30.9 billion by 2025. Connected devices and services create enormous amounts of data, and IDC forecasts that by 2025 the global data will grow to 163 zettabytes (that is a trillion gigabytes). That’s ten times the 16.1ZB of data generated in 2016. All this data will unlock unique user experiences and a new world of business opportunities. Where once data primarily drove successful business operations, today it is a vital element in the smooth operation of all aspects of daily life for consumers, governments, and businesses alike. In just the past 10 years society has witnessed the transition of analog to digital. What the next decade will bring using the power of data is virtually limitless.
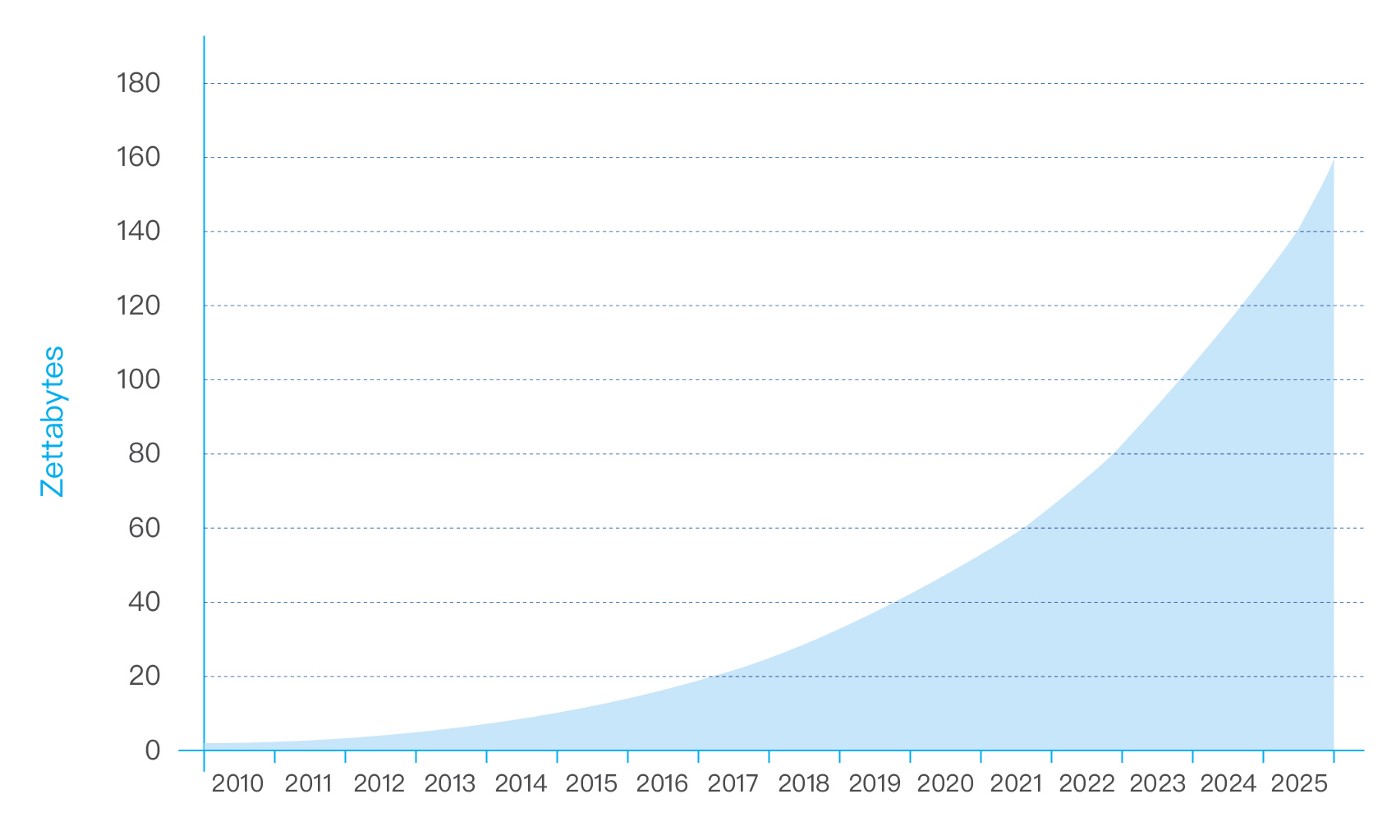
The trends of global data privacy protection
In Data Age 2025[2], IDC identified artificial intelligence and security as critical foundations.
Artificial intelligence that change the landscape. The emerging flood of data enables artificial intelligence technologies to turn data analysis from an uncommon and retrospective practice into a proactive driver of strategic decision and action. Artificial intelligence can greatly step up the frequency, flexibility, and immediacy of data analysis.
Security as a critical foundation. All this data from new sources open up new vulnerabilities to private and sensitive information. There is a significant gap between the amount of data being produced today that requires security and the amount of data that is actually being security protected, and this gap will widen. By 2025, almost 90% of the global data will require certain level of security, but less than half will be security protected.
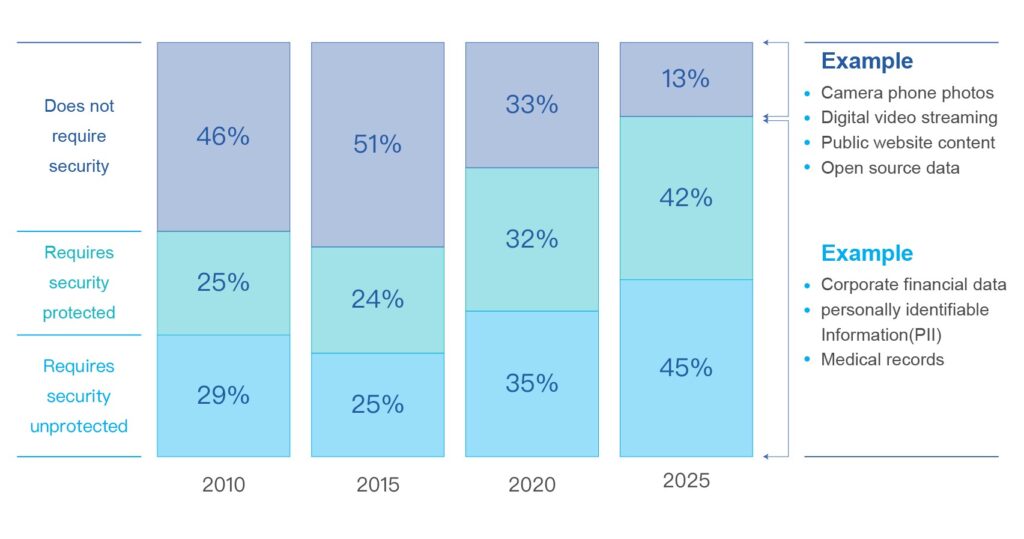
According to a report released by the International Data Corporation (IDC) on February 21, China’s data circle will increase to 48.6 ZB bytes in 2025, accounting for 27.8% of the world, making it the largest data circle.
The report predicts that China’s data circle will lead the world with an average annual growth rate of 30% from 2018 to 2025, 3% higher than the world.
In addition, from 2015 to 2025, China’s data circle has expanded at a rate of 14 times, and the value contained in it is incalculable. Such a large-scale data presents both opportunities and challenges for companies and governments in it, effectively and reasonably Mining the value of data will become an important boost to promote economic growth.
IDC also pointed out that in 2018, 56% of the data in the data circle needs to be secured, and it will increase to 66% by 2025. The development of the Internet of Things will promote the growth of real-time data. By 2025, the proportion of real-time data will reach 29%. The challenges that fragmentation brings to data identification, classification, management, security, and applications are also issues that enterprises need to face. Companies in the data ecosystem must gain insight into data development trends and formulate reasonable data management and application strategies to further enhance their corporate value and competitiveness in the data planet.
“Data is the new oil, the most precious asset of this century!” According to estimates, in recent years, data is doubling every 18 months, and the growth rate is accelerating. In today’s world, big data has had a major and profound impact on social governance, state management, people’s lives, and economic development. At present, all countries regard information technology and big data as an important driving force for innovation and development.
Data leakage
In the 21st century, many companies around the world, including Internet giants, have been exposed to data breaches and abuses. Google, Amazon, Facebook, Apple and other US Internet companies have been fined by the European Union for data privacy, monopoly, and taxation issues in Europe in the past two years. , Has aroused widespread global attention, and also made people gradually realize the importance of personal privacy protection.
Case 1:

On September 4, a user sold a database of 3.8 billion Clubhouse and Facebook user records on a well-known hacker forum. The hacker claimed that the database contained 3.8 billion mobile phone numbers from Clubhouse’s private database and Facebook.
Researchers compiled and found that the database contains user names, mobile phone numbers and other data. Judging from the post selling data, the price of the complete 3.8 billion records is $100,000, and hackers can also split the database and sell it to buyers who are willing to buy it.
At present, researchers have not confirmed the authenticity of the database, but the database may be a piece of the leaked Facebook profile data with other leaked data.
But if the leaked information is true, it is a gold mine for spam attackers. If the leaked information is true, the attacker can obtain more information about the owner of the leaked mobile phone number based on the existing information, including user name and location information based on the mobile phone number prefix. Therefore, attackers can easily forge personalized spam based on the leaked information and launch large-scale spam attacks.
Case 2:

The Telegraph (British Daily Telegraph) is the largest selling of the four national “premium” daily newspapers in the UK. Recently, The Telegraph was exploded due to inadequate database security protection measures, which caused 10 TB data leak. The leaked information includes internal logs, subscriber names, emails, device information, URL requests, IP addresses, authentication tokens, and unique reader identification codes.
On September 14, security researchers discovered that the database has no any protection, and they confirmed that at least 1200 unencrypted address book information can be accessed without a password.
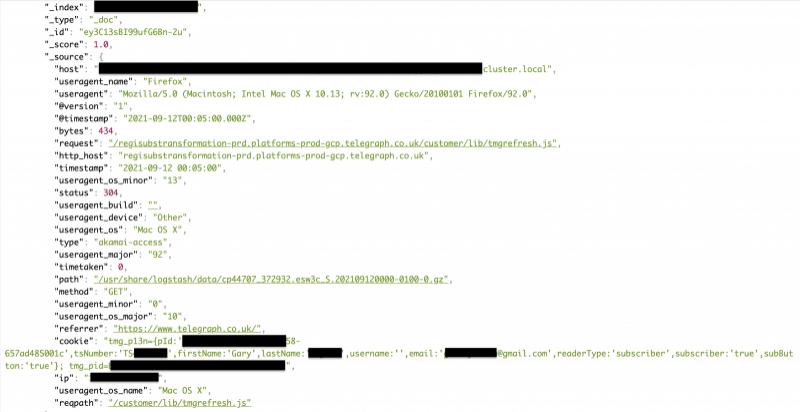
The leaked URL request may be used to reconstruct the user’s browsing history, causing privacy risks. The main risk for such users is that they may be exposed to spam or phishing emails.
Legislative protection

The disorderly circulation and sharing of data may lead to major risks in terms of privacy protection and data security, which must be regulated and restricted.
For example, in view of the frequent privacy and security issues caused by the improper use of personal data by Internet companies, the European Union has formulated the “most stringent” data security management regulation in history, the General Data Protection Regulation (GDPR). ), and officially took effect on May 25, 2018. After the Regulations came into effect, Internet companies such as Facebook and Google were accused of forcing users to agree to share personal data and faced huge fines and were pushed to the forefront of public opinion.
On January 1, 2020, the California Consumer Privacy Act (CCPA), known as the “most stringent and comprehensive personal privacy protection act” in the United States, will come into effect. CCPA stipulates new consumer rights aimed at strengthening consumer privacy and data security protection. It involves the access, deletion and sharing of personal information collected by enterprises. Enterprises have the responsibility to protect personal information. Consumers control and own their personal information. Information, this is the most typical state privacy legislation in the United States at present, and it has raised the standards of privacy protection in the United States. In this case, the typical Internet business model that used Internet platforms to collect user data centrally to achieve platform-based precision marketing will face major challenges.
China has also carried out a long period of work in the protection of personal information. Aiming at the protection of personal information in the Internet environment, it has formulated the Decision of the Standing Committee of the National People’s Congress on Strengthening the Protection of Network Information and Provisions on the Protection of Personal Information of Telecommunications and Internet Users and The Decision of the Standing Committee of the National People’s Congress on Maintaining Internet Security,and the Consumer Rights Protection Law and other relevant legal documents.
In particular, on November 7, 2016, the Network Security Law of the People’s Republic of China passed by the Standing Committee of the National People’s Congress clarified the requirements for the collection, use and protection of personal information, and stipulated that individuals should correct or delete their personal information. right. In 2019, the Central Cyberspace Administration of China issued the “Measures for the Administration of Data Security (Draft for Solicitation of Comments)” to openly solicit opinions from the public, clarifying the relevant standards and norms for the collection, processing, use, and safety supervision and management of personal information and important data. It is believed that these laws and regulations will play an indispensable and important role in promoting the compliant use of data, protecting personal privacy and data security. However, it is necessary to formulate special data security laws and personal information protection laws from the perspective of systematization, ensuring consistency, and avoiding fragmentation.
Generally speaking, the current laws and regulations related to information security in our country are based on the National Security Law and the Cyber Security Law, and are based on the cyber security level protection system, the critical information infrastructure protection system, and data localization and cross-border This is reflected in the mobile system. At the same time, ” and the upcoming Personal Information Protection Law are the mainstay.
In terms of the legislative positioning of the three laws, the Data Security Law is the basic law in the field of data security. In parallel with the current Cyber Security Law and the upcoming Personal Information Protection Law, it has become the third of cyberspace governance and data protection. Driving a carriage, the Cyber Security Law is responsible for the overall governance of cyberspace security, the Data Security Law is responsible for the security and development and utilization of data processing activities, and the Personal Information Protection Law is responsible for the protection of personal information.
The flow of data

In the current climate, individuals and organizations are reluctant to share personal and professional data due to data privacy and misuse issues and increased data regulation, AI organizations with limited resources do not have access to larger valid datasets to train better models, and published models can quickly become out of date without effort to acquire more data and re-train them. As a result, the focus of AI has shifted from an orientation centered on AI-based algorithms to an orientation centered on big data architectures that guarantee security and privacy. Isolation of data and protection of data privacy is becoming the next challenge in AI.
As a core production factor in the digital age, data can only maximize the value of data assets when it is widely used, and the maximum use of resources is from exclusive to shared. Open sharing requires:
1.The flow of data
As a special asset, data can create new value continuously only in the process of circulation and use. Therefore, data flow is “normal”, while data storage at rest is “abnormal”. The cross-domain flow of data across departments, fields, and industries will occur frequently. This is in sharp contrast with traditional data, which is limited to information islands, which are often static.
2The business environment will be more open
The business ecology will be more complex, the roles involved in data processing will be more diverse, and the boundaries of systems, businesses, and organizations will be further blurred, resulting in data generation, flow, and processing processes that are richer and more diverse than before. This is completely different from the traditional “self-produced and self-sold” method of local data.
With the increasing emphasis on data liquidity, different countries and regions such as China, the European Union, and the United States are choosing appropriate systems to ensure data liquidity. These data must be based on the inherent rights of sovereign states. The core logic is to extend and expand the basic value pursuit of traditional national sovereignty concepts in the field of cyberspace and data, to ensure that the country has the highest rights of independent development, possession, management and disposal of its own data.
Artificial intelligence

During the last 5 to 10 years, the rapid growth of the Internet, mobile Internet and Internet of Things has generated enormous amounts of data. The increase in chip processing power, the popularity of cloud services and the decline in hardware prices have led to a significant increase in computing power. The broad industry and solution market has enabled the rapid development of AI technology. AI has been everywhere in human’s daily life, and AI has been applied in many industry verticals such as medical, health, finance, education, and security.
According to Mind Commerce’s AGI report, the global market for general AI for enterprise applications and solutions will reach $3.83 billion by 2025, and the global market for AGI-enabled big data and predictive analytics will reach $1.18 billion. By 2027, 70% of enterprise and industrial organizations will deploy AI-embedded intelligent machines, more than 8% of global economic activity will be done autonomously by some kind of AI solution, compared to less than 1% today, and more than 35% of enterprise value will be directly or indirectly attributable to AGI solutions.
Challenges with Artificial Intelligence
Data Privacy and Security Regulations
Machine learning technology, mainly deep learning, cannot be learned and inferred without enormous amounts of data, so enormous amounts of data becomes one of the most important resources for the development of frontier technology of artificial intelligence. Technology giants, especially those in China and the United States, have accumulated huge amounts of data through the Internet services, and as the value of data becomes increasingly prominent in the era of AI, these data will gradually evolve into an important asset and competitiveness of enterprises. According to IDC estimates, the global data volume is expected to reach 44 ZB in 2020, and China’s data volume will account for 18% of the global data volume, reaching 8060 EB (equal to 7.9 ZB) in 2020.
The more “intelligent” artificial intelligence is, the more personal information data needs to be acquired, stored and analyzed, which will inevitably involve the important ethical issue of personal privacy protection. Today, all kinds of data and information are collected all the time and everywhere, almost everyone is placed in the digital space, personal privacy is very easy to be stored, copied and spread in the form of data, such as personal identity information data, network behavior trajectory data, as well as data processing and analysis of preference information, prediction information, etc. It is foreseeable that in the near future, more and more artificial intelligence products will come into thousands of households, which will bring convenience to people’s lives while also easily accessing more data information about personal privacy.
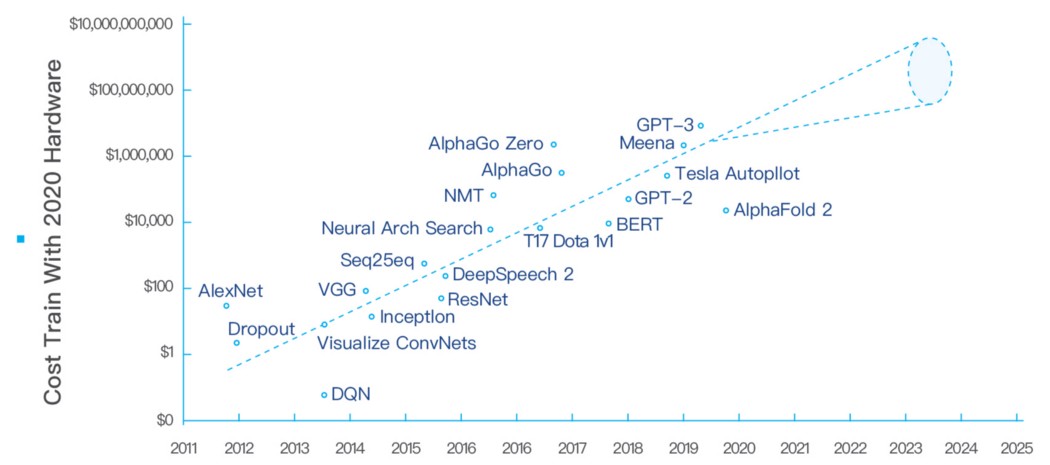
Expensive training costs
While advances in hardware and software have been driving down AI training costs by 37% per year, the size of AI models is growing much faster, 10x per year. As a result, total AI training costs continue to climb. ARK[8] believe that state-of-the-art AI training model costs are likely to increase 100-fold, from roughly $1 million today to more than $100 million by 2025.
Resource centralization
While AI has made tremendous progress, the benefits of AI are not widely used, AI has not yet been democratized, and there is a trend toward increasing centralization.
Most AI research is controlled by a handful of tech giants. Independent developers of AI have no readily available way to monetize their creations. Usually, their most lucrative option is to sell their technology to one of the tech giants, leading to control of the technology becoming even more concentrated.
A few tech giants have monopolized the upstream of data by providing services to consumers, gaining unprecedented access to data, training high-end AI models and incorporating them into their ecosystem, further increasing the dependence of users and other companies on the five giants. Except for a few tech giants, other market players such as small and innovative companies find it difficult to collect large-scale data, and even if they obtain data at a significant cost, they lack effective usage scenarios and are unable to exchange them, making it difficult to precisely align with relevant AI learning networks.
Most organizations face an AI skills gap, and the core resource for filling that gap is AI talent, including AI researchers, software developers and data scientists. But tech giants are strategically working to monopolize AI talent at an unprecedented rate and scale, and these companies’ AI developers are available only to advance their employers’ goals.
With the development of the Internet age, massive amounts of data are generated all the time. These massive amounts of data not only contain great value, but also contain a lot of personal privacy. The development of artificial intelligence is inseparable from massive amounts of data. However, the monopoly and immobility of data hinders the development of artificial intelligence.
Data Security

Data security is not a new concept. It has been more than ten years since the birth of the first representative data security product-Data Leakage Prevention Product (DLP), and data security and related products have gradually been accepted. Data security has become a hot topic, and the security of big data has also become a serious issue.
As blockchain technology appears more and more in people’s field of vision, its decentralized nature has subversively solved many “trust” issues and provided a consistent guarantee for multiple companies and units to participate in projects. It provides platform support for data security, data value-added, and achievement identification, and encourages all participants to be more proficient in cooperation and focus on the research work itself, reducing the risk of data leakage.
Blockchain consensus algorithms can help subjects in decentralized AI systems collaborate to accomplish tasks. For example, in the field of intelligent transportation, AI is the “brain” behind countless autonomous vehicles, and these autonomous vehicles need to cooperate with each other trustfully to accomplish a common goal.
Of course, the collaboration of these autonomous vehicles could rely on trusted third parties, which would expose the public to security and privacy issues.Artificial intelligence models require massive amounts of high-quality data for training and optimization, and data privacy and regulation prevent effective data sharing. Blockchain and privacy-preserving computation enable the privacy and security controls needed for compliance and facilitate data sharing and value exchange.
The intersection between artificial intelligence and cryptography economics is another interesting area where blockchain combined with AI can enable the monetization of data and incentivize the addition of a wider range of data, algorithms and computing power to create more efficient artificial intelligence models.Blockchain can make AI more coherent and easy to understand, with an untamperable record of all data, variables and processes used in AI training decisions that can be tracked and audited.
The circulation of data and the safe use of data by artificial intelligence are bound to be the general trend in the future.
PlatON 2.0
The mission and goals of PlatON
Combining blockchain and privacy-preserving computation technologies, PlatON is building a decentralized and collaborative AI network and global brain to drive the democratization of AI for safe artificial general intelligence.
Privacy-preserving Artificial Intelligence Network
- Decentralized privacy-preserving computation network, establishing a decentralized data sharing and privacy-preserving computation infrastructure network that connects data owners, data users, algorithm developers and arithmetic providers.
- A decentralized AI marketplace that enables the common sharing of AI assets, agile smart application development, and provides the whole process of products and services from AI computing power and algorithms to AI capabilities and their production, deployment, and integration.
- A decentralized AI collaboration network that allows AI to collaborate at scale, bringing together collective intelligence to accomplish complex goals.
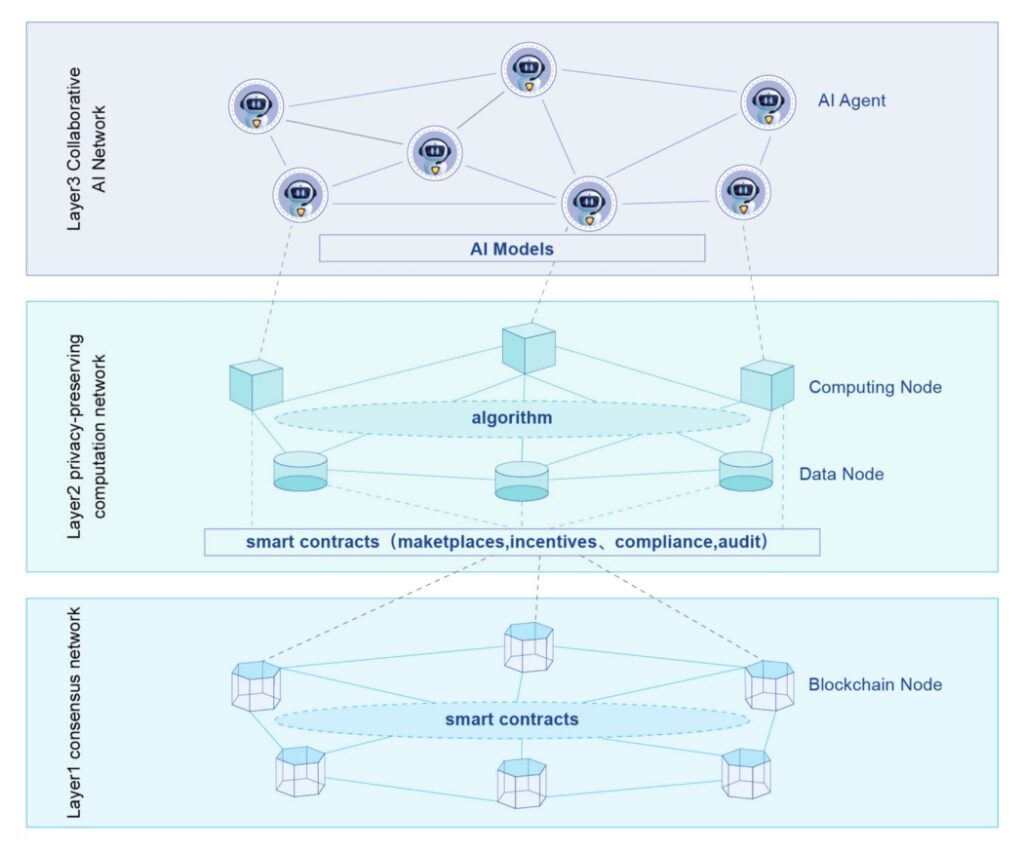
Three−Tier AI network model of Privacy-preserving Artificial Intelligence Network
Layer1: Consensus Network
Layer1 is the basic protocol of blockchain, the core is consensus and smart contract, Layer1 is the basis of decentralized computing, smart contract is a simple computing model, in a sense it is a kind of Serverless.
Layer2: Privacy-preserving computation network
The data in privacy-preserving computation networks are generally kept locally and are available invisible through secure multi-party computing, federated learning, and other techniques for collaborative computation. Not only the privacy of the data is protected, but also the privacy of the computation results such as the completed AI models trained.
Layer3: Collaborative AI network
Using the datasets and computing power of privacy-preserving computation networks, AI models can be trained, deployed, and served externally, forming a marketplace for AI services. Through technologies such as Multi Agent System, AI agents can operate independently and communicate and collaborate with each other to create more and more innovative AI services, enabling AI DAO and forming autonomous AI networks.
Competitive Advantages
- Decentralization
Any user and node can connect to the network permissionless. Any data, algorithms and computing power can be securely shared, connected and traded. Anyone can develop and use artificial intelligence applications.
- Privacy-preserving
Modern cryptography-based privacy-preserving computation techniques provide a new computing paradigm that makes data and models available but not visible, allowing privacy to be fully protected and data rights to be safeguarded.
- High-performance
High-performance asynchronous BFT consensus is achieved through optimization methods such as pipeline verification, parallel verification, and aggregated signatures, and its safety, liveness, and responsiveness are proven using formal verification methods.
- Low training costs
With blockchain and privacy-preserving computation technologies, anyone can share data and algorithms in a secure and frictionless marketplace, truly reducing marginal costs and drastically reducing training costs.
- Low development threshold
Visualize AI model development and debugging, automated machine learning (AutoML), MLOps simplifies the whole process of managing AI models from model development, training to deployment, reducing the development threshold of AI models and improving development efficiency.
- Regulatable and auditable
All data, variables, and processes used in the AI training decision-making process have tamper-evident records that can be tracked and audited. The use of privacy-preserving technologies allows the use of data to satisfy regulatory regulations such as the right to be forgotten, the right to portability, conditional authorization, and minimal collection.
👇👇👇
PlatONWorld — the base of PlatON ecological long-termists!
Welcome everyone to continue to pay attention to PlatONWorld!
PlatONWorld | Official website platonworld.org
PlatONWorld | Telegram
PlatONWorld | WeChat:mcqueen678

Publisher:PlatONWorld-TY,Please indicate the source for forwarding:https://platonworld.org/?p=5303



