In blockchain semantics, BFT consensus is a mechanism that attempts to get N validator nodes (of which there are at most f Byzantine nodes) to agree on an infinitely growing sequence of proposals (blocks or sets of transactions).
It is well known that classical BFT-based consensus algorithms, either PBFT or the improved HotStuff, have relatively high communication complexity, and are poorly scalable and have high latency in the presence of network instability.
In recent years, with the widespread use of DAG technology on the blockchain, a DAG-based BFT consensus has been proposed and continuously improved, taking advantage of the efficient implementation of DAG and its natural asynchronous communication mechanism to enhance the scalability of consensus, shorten confirmation time and increase transaction throughput. However, as an asynchronous operation, DAG does not have a global ordering mechanism, which makes it likely that the data stored between nodes will deviate after a certain period of time, and in such deviation, how to finally agree on the sequence is the key to DAG consensus.
This article will first introduce the underlying theory: DAG-based consensus and round-based DAG consensus, and then explain in detail the DAG-Rider, Tusk and Bullshark protocols.
DAG Based BFT Consensus
According wikipedia, DAG is defined as “In mathematics, particularly graph theory, and computer science, a directed acyclic graph (DAG) is a directed graph with no directed cycles. That is, it consists of vertices and edges (also called arcs), with each edge directed from one vertex to another, such that following those directions will never form a closed loop. A directed graph is a DAG if and only if it can be topologically ordered, by arranging the vertices as a linear ordering that is consistent with all edge directions. DAGs have numerous scientific and computational applications, ranging from biology (evolution, family trees, epidemiology) to information science (citation networks) to computation (scheduling).”
DAG is also being used in blockchain consensus algorithms, as an infinite graph with forever growing transactions forming infinite blocks pointing to each other with out a closed loop. As a normal graph, it has group of vertices and group of edges.
G=(V(G),E(G),ψG)
In case of DAG, for each vertex v, there are Ev− and Ev+ to indicate the incoming and outgoing edgedirections, also called arc.
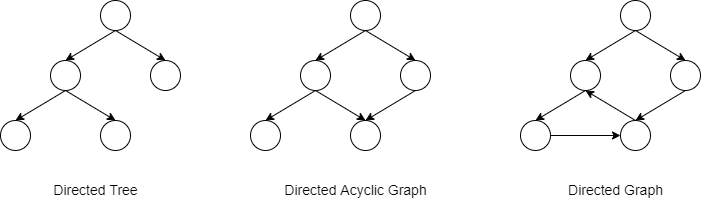

Samples of Directed Tree, DAG graph, and Directed Graph
The above is a diagram of a directed tree, a DAG graph and a directed graph, from which you can see the difference between the three.
- Directed trees: each vertex can only point to one previous vertex, and the whole data flow has a clear direction
- DAG graph: each vertex can point to more than one previous vertex, and the entire data flow has a clear direction
- Directed graphs: Unlike DAGs, directed graphs allow data to flow back, and the entire structure has a non-obvious direction of data flow
Application of DAG in blockchain consensus
In a DAG-based blockchain consensus, each consensus message contains a proposal (a block or a set of transactions) and a set of references to previous consensus messages, where references can be understood as meaning that each new message must explicitly refer to a number of previous messages, and a reference to a message indicates an endorsement and a vote on that message.(We simply refer a consensus message as a message moving forward.)
Representing above to a DAG graph, a message is a vertex and its reference to another message is an edge, so that all consensus messages together form a growing DAG graph
DAG based consensus is constructed into two layers
- Communication layer: reliably broadcast and receiving proposals, as well as voting, with some metadata that help to form a Directed Acyclic Graph (DAG) of the messages they deliver
- Zero-overhead ordering layer: without any extra communication from any validators, each validator could generate the common ordering of all delivered proposals or messages, solely by processing local DAG copies. And this guarantees that all validators eventually agree on the serial commit order of proposals.
Due to the asynchronous nature of the network, the DAG snapshot of validators may be slightly different at any given time, from message generation to finalization, so how to ensure that all validators eventually agree on the correct processing order is the key and difficult part of all DAG-based consensus algorithms. Let’s name it consistency difficulty challenge.
Comparison with classic BFT
The classic BFT-based consensus algorithm, either PBFT or the improved HotStuff, requires a Leader node to collect transactions to generate blocks, broadcast and receive votes from other nodes, and finally reach a consensus on block producing after three stages of interaction (pre-prepare, prepare, commit), with the protocol relying more on the reliable delivery of consensus messages between nodes.
DAG-based consensus, on the other hand, uses the DAG graph theory to decouple the network communication layer focusing on the message propagation from the consensus logic (proposal ordering). The benefit of this separation is that each node can compute the consensus state and processing order asynchronously, thus reducing latency and network overhead during communication, which, together with the efficient implementation of DAG, makes DAG-based consensus highly scalable and high-throughput.
Round-based DAG BFT consensus
In a round-based DAG BFT, each vertex is associated with an integer round number. Each validator node broadcasts only one message per round, and each message references at least N−f messages from the previous round. That is, in order to advance to round r, the validator node first needs to obtain N−f messages from different validator nodes in round r−1.
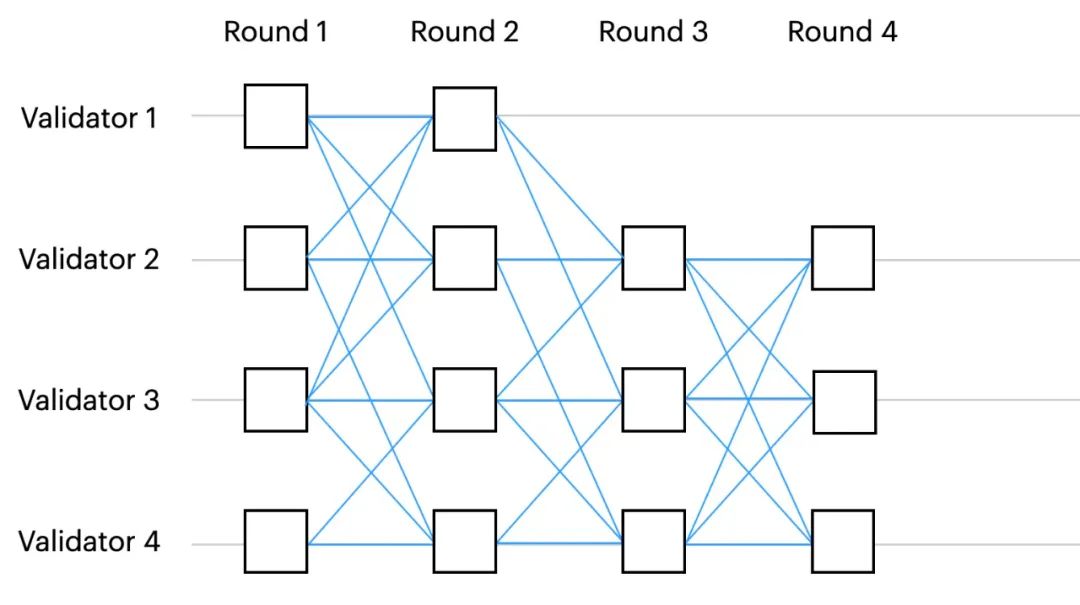
The diagram above shows an example of a round-based DAG BFT with 4 validator nodes, where each message in each round references at least 3 messages from the previous round, and if a round fails to collect all 3 messages it cannot advance to the next round.
This is somewhat similar to the HotStuff algorithm, where each block voting message must carry the parent quorum of the previous block, as this ensures that the majority of nodes in the network advance to the next round in an orderly and balanced manner, which is the basis of quorum-based BFT fault-tolerant consensus
Three characteristics
In a round-based DAG BFT consensus protocol, when a message (or a vertex) is confirmed to be inserted into a DAG, it has the following guarantees.
- Reliability: a copy of the message is stored on enough validator nodes so that it can eventually be downloaded by all honest participating nodes
- Non-equivocation: for any validator node v in round r, if two validator nodes have a vertex from v in r in their local view, then both validator nodes have identical vertices and identical inter-vertex reference relations
- Causal ordering: Messages carry an explicit reference to the previous round of delivery messages. Therefore, this ensures that any validator node that has committed a vertex will also have exactly the same causal history (referenced messages from previous rounds) for that vertex in their local view
The round-based DAG BFT consensus protocol allows each validator node to observe only its local DAG graph, but also to finally agree on the commit sequence, which is the key to solving the aforementioned consistency difficulty challenges.
Also, because these features eliminate the ability of Byzantine nodes to do evil, the consensus logic can be simplified compared to traditional BFT algorithms, making the protocol design simpler.
DAG-Rider
In the DAG-Rider protocol, each validator node divides the local DAG graph into waves in 4 consecutive rounds, and in the last round of each wave, a leader is randomly selected from the first round and tries to commit that vertex as leader.
In the figure below, each horizontal line represents four different validator nodes, and each vertex represents the consensus messages sent by different validation nodes in each round.
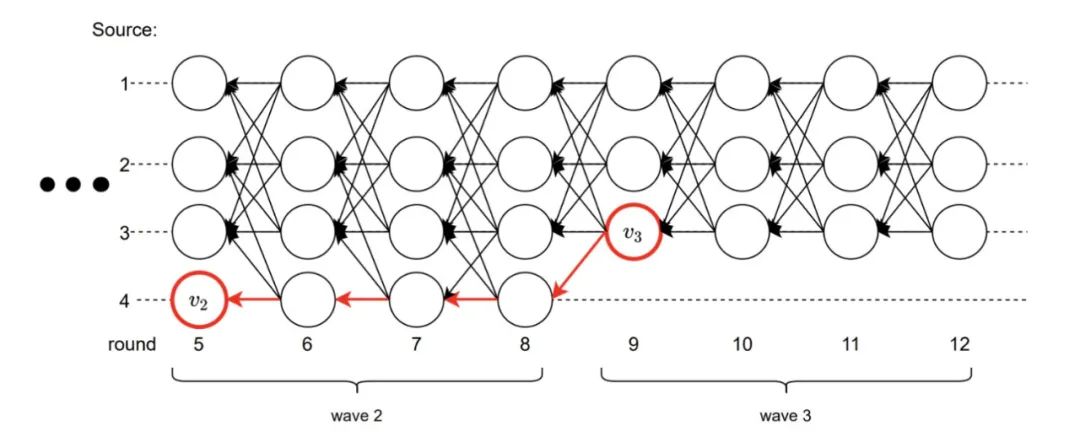
The vertex commit process:
1.attempt to commit vertex v2in round8 of wave2, but since only two vertices (less than 2f+1) lead to v2 in round8, v2 does not satisfy the commit criteria at round8.
2.since there are 2f+1vertices leading to v3 in round12, v3 satisfies the leader commit criteria.
3.Also, since there is a path from v3 to v2, v2 is committed first then v3 in wave3.
How to ensure final consistency of commits
Due to the asynchronous nature of the network, the local DAG graphs of different validator nodes may be slightly different at any given time. That is, some vertices may be committed by some nodes (here, M1) at the end of a wave, while some nodes (M2) go directly to the next wave without committing.
This is unlikely to happen. The fact that M1 can commit vertex v2 means that there are at least 2f+1 vertices to v2 in round8, and v3 in round9 must refer to at least 2f+1 different vertices from the previous round, so there is at least f+1 path to v2 in v3.
Tusk
The design idea of Tusk is based on the DAG-Rider and did some improvements. In Tusk each wave contains 3 rounds and the last round of each wave is the first round of the next wave.
In the following figure, r1~r3denote wave1, r3~r5 denote wave2, and the vertices L1 and L2 are the leaders of the two randomly selected waves respectively
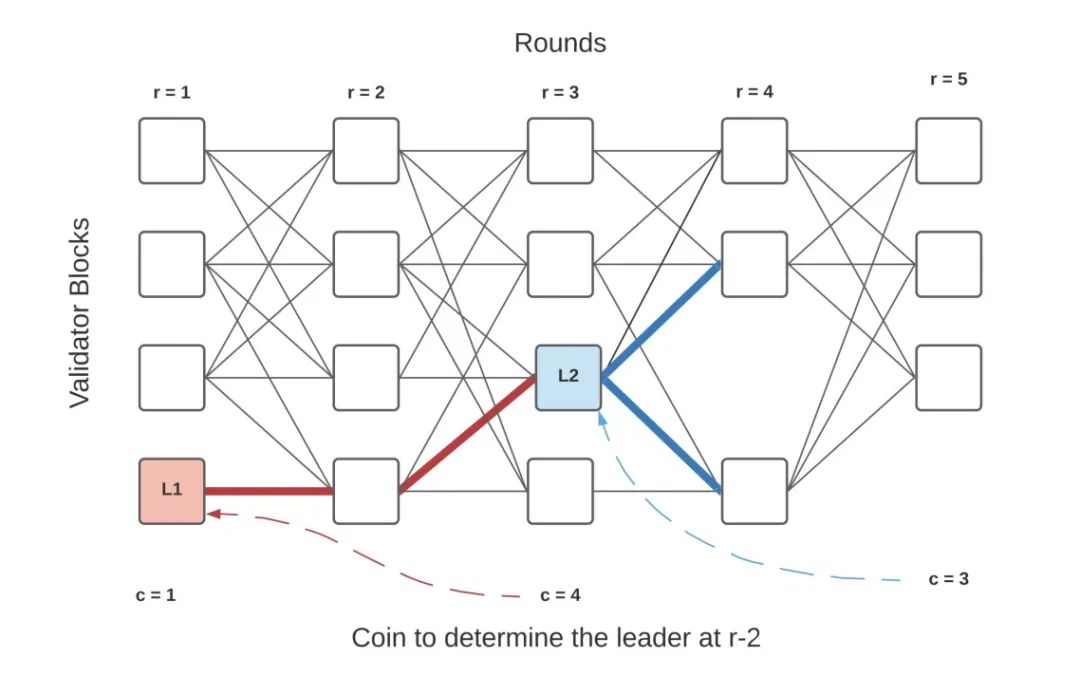
Vertex commit process:
1.in round1, each validator node generates blocks and broadcasts them
2.in round2, each validator node votes on the vertices from the previous round (i.e. referencing the vertices from round1)
3.in round3 a random coin is selected (i.e. a random leader is chosen in round1, L1 in the diagram)
4.if f+1 vertices in round2 refer to L1, then commit it, otherwise go straight to the next wave
When L2 is elected, L2 is referenced by more than f+1vertices in round4, L2 meets the commit rule, and L2 has a path to L1, so L1−>L2 is the committe order in wave2.
Similarly, if some nodes commit L1 in wave1, it means that round2 has at least f+1vertices to L1, and L2 in round3 must refer to at least 2f+1different vertices from the previous round, so L2 has at least one path to L1. This ensures that all validation nodes eventually agree on the order of commit.
Comparison with DAG-Rider
In the regular case, DAG-Rider requires 4 rounds to commit a vertex, whereas Tusk only requires 3 rounds to commit, reducing the submission latency.
However, with 4 rounds of voting, DAG-Rider guarantees that the probability of being able to commit a vertex in each wave is at least 2/3, whereas Tusk has 1/3 probability of being able to commit a vertex in each of its waves because there is one less round of voting.
That is, in the asynchronous case, the DAG-Rider needs only 3/2 waves (6 rounds) to commit a vertex, while Tusk needs 3 waves to commit a vertex. It is known that each wave contains 3 rounds, and the last round of each wave is the first round of the next wave, so Tusk needs 7 rounds to commit a vertex.
Bullshark
Bullshark’s paper presents two versions of this protocol.
- Asynchronous version: In the regular case, it takes only 2 rounds to commit a vertex. Further reduction in commit latency compared to DAG-Rider and Tusk
- Partially synchronous version: improves on Tusk by requiring only 2 rounds to commit a vertex, reducing the latency of outgoing block rounds
Asynchronous version
Similar to the DAG-Rider, each wave in the asynchronous protocol version also contains 4 rounds. However, BullShark has 3 leaders in each wave, a randomly selected fallback leader from the first wave and a predefined steady-state leader in the first and third waves.
In the figure below, S1A and S1B are the steady-state leaders and F1 is the fallback leader (randomly generated in the last round of each wave).
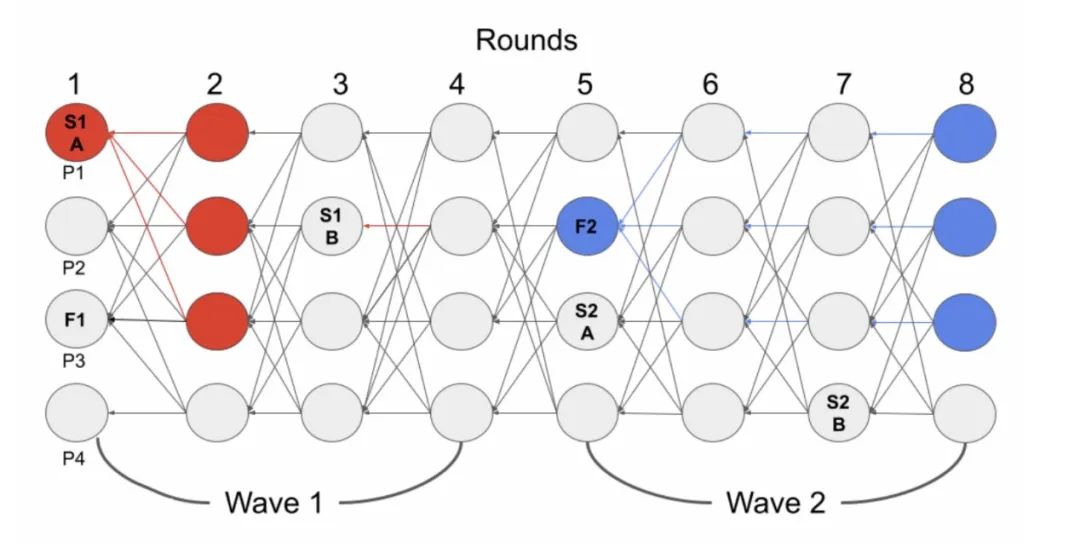
Vertex commit process:
1.in round2, the node finds that 2f+1 nodes have voted for S1A, so it can commit S1A
2.in round4, the node finds only one vote for S1B, it cannot commit S1B, and the vote type of the validator node in wave2 changes to fallback type
3.in round5, the node observes the other 2f+1nodes in round4 and finds that none of them can commit S1B either, so the current node can determine that all other nodes in wave2 have fallback voting type, and the steady-state leaders (S2A and S2B) in wave2 have lost the opportunity to commit.
4.In round8, the node finds that 2f+1 nodes have voted for F2 and can commit F2. It tries to commit S1B before committing F2, but since S1B does not satisfy the commit rule (there are less than f+1 references to S1B in the local view of the current node), it only commits F2.
As can be seen, in the regular case, a steady-state leader can be committed every two rounds, which is a further optimization compared to the Tusk protocol, and the fallback leader design ensures that the consensus remains active even under the worst asynchronous conditions.
Source code interpretation
Pseudo-code for commit:

From the try_orderingfunction we can see that
- In
round%4==1: try to commit the steady-state leader or fallback leader from round 3 of the previous wave and confirm the voting status of yourself and the rest of the validator nodes in the current wave
- In
round%4==3: only the steady-state leader of the 1st round of the current wave needs to be committed.
From try_steady_commit and try_fallback_commit, we see that 2f+1 is used as the number of votes to be committed by a vertex, as opposed to Tusk’s f+1, because Bullshark needs to determine not only whether the vertex is ready to be committed, but also whether most (no less than 2f+1) of the nodes will be in the same voting state in the next wave.
Commit Leader
As we know from the previous section, when committing a vertex, we can already be sure that there are at least 2f+1nodes of the same voting type as us in the current wave.
What commit does is to recursively commit vertices from the previous round that have not been committed for a while, if we are sure that we can commit a vertex.
When the leader has been able to be committed by other nodes in the previous round, it satisfies the condition that there are at least 2f+1 votes and at least 2f+1 nodes in the same voting state, so that for the current verification there are at least f+1 votes in its local view.

Partial synchronization version
This version simplifies the Tusk consensus protocol for easier code implementation and is the version currently implemented in the Sui consensus mechanism.
Unlike Tusk where all leader vertices are randomly generated, the Bullshark Partial Synchronization version of the DAG has a predefined leader vertex for each odd-numbered round (highlighted in solid green below). The rules for committing vertices are simple: a leader is committed if it receives at least f+1 votes in the next round; in the figure, L3 is committed with 3 votes, while L1 and L2 have less than f+1 votes and are not committed.
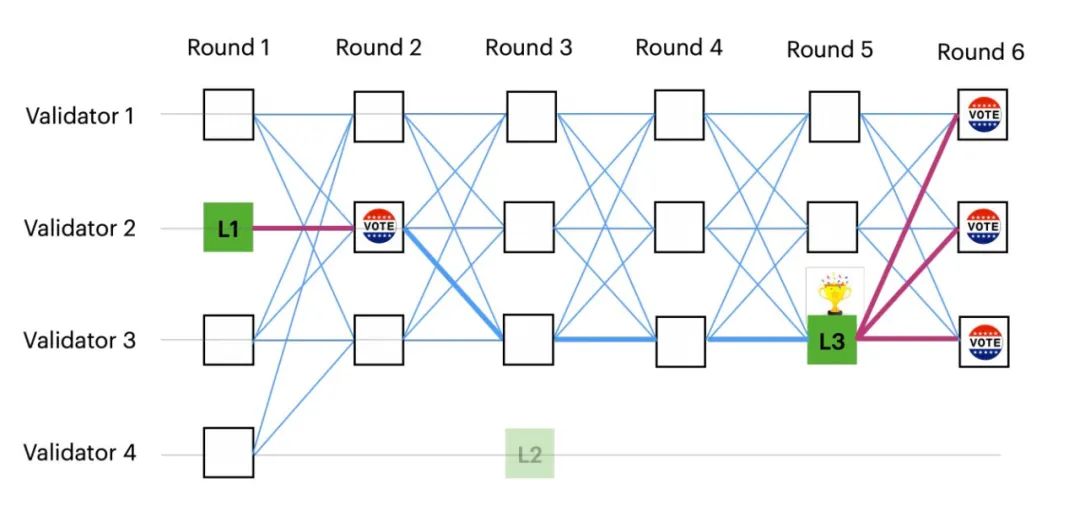
However, due to the asynchronous nature of the network, the local view of the DAG may be different for different validator nodes. Some nodes may have successfully committed L1 and L2 vertices in previous rounds, so when committing L3 vertex, it is necessary to start from L3 to see if there is a path to L2 and L1, and if so, the vertices from previous rounds need to be committed first. In the diagram there is no path from L3 to L2, so we can skip L2, but there is a path from L3 to L1, so we commit L1 ahead of L3.
Performance comparison
Referring to the Bullshark paper, here is a comparison of the latency and throughput of the HotStuff, Tusk and BullShark protocols for different numbers of validator nodes in the regular case.
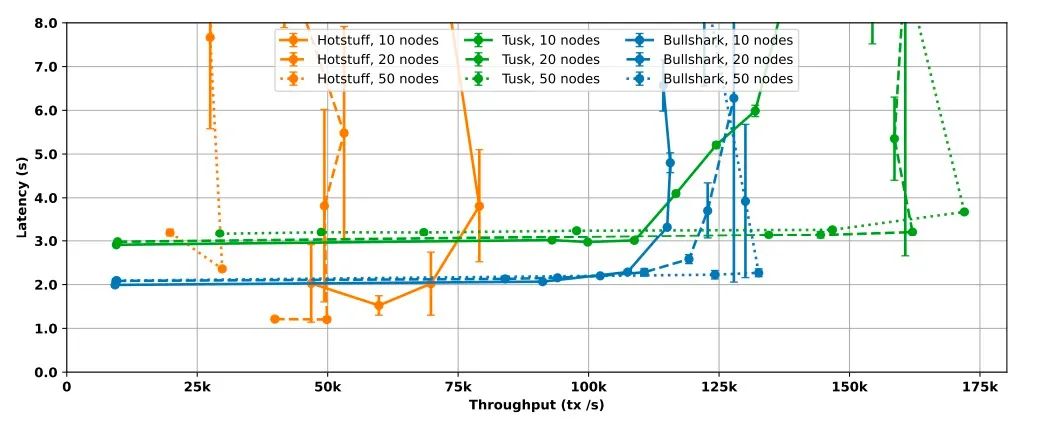
- HotStuff: Throughput is 70,000 tx/s, 50,000 tx/s and 30,000 tx/s for 10, 20 and 50 validator nodes consensus respectively, HotStuff has been shown to not scale well when increasing node size, but it has low latency of about 2 seconds
- Tusk: Tusk’s throughput is significantly higher than HotStuff, peaking at 110,000 tx/s for a 10 validator nodes consensus and around 160,000 tx/s for 20 or 50 nodes, with throughput increasing with node size (thanks to the efficient implementation of DAG). Despite the high throughput of Tusk, it has a higher latency than HotStuff, around 3 seconds
- BullShark: BullShark strikes a balance between the high throughput of Tusk and the low latency of HotStuff. It also has significantly higher throughput than HotStuff, reaching 110,000 tx/s and 130,000 tx/s for the 10 and 50 validator nodes consensus respectively, while observing in the graph that its latency is around 2 seconds regardless of number of nodes.
Conclusion
- The theoretical starting point of the Tusk protocol is the DAG-Rider, an improved version of the DAG-Rider, which reduces the latency of outgoing block rounds in the general case.
- Bullshark’s version of synchronization builds on Tusk’s optimizations, further reducing latency and making it simpler to implement. However, like HotStuff, it has no liveness guarantee in case the final synchronization assumption does not hold.
- The asynchronous version of Bullshark adds a fallback voting mode to the steady-state mode, giving it the same low latency as the synchronous version in the regular case, and still guarantees activity in the asynchronous case.
In this article we have looked at three types of round-based BFT consensus, but there are many other DAG-based BFT consensuses, such as Fantom’s lachesis, which do not strictly follow a round-based algorithm, and which open up a new way of thinking. It is believed that as more projects join in, DAG consensus will become more complete and diverse, providing more room for imagination to enhance the scalability of the blockchain.
References:
1.DAG-Rider paper: [PODC 2021]All You Need Is DAG
2.Narwhal and Tusk paper:[2105.11827] Narwhal and Tusk: A DAG-based Mempool and Efficient BFT Consensus
3.Bullshark paper: [To appear at CCS 2022] Bullshark: DAG BFT Protocols Made Practical
4.DAG Meets BFT – The Next Generation of BFT Consensus
5.Narwhal, Bullshark, and Tusk, Sui’s Consensus Engine | Sui Docs
This article is reproduced from https://platon.network/informationDetail?id=185&plat=1



