Overview
Privacy-Preserving Computing Infrastructure
With the rapid growth of the Internet, the Internet giants represented by FAANG and BAT, by virtue of their technological monopoly status, have collected and stored enormous user data. And with the use of big data and AI, they are enjoying data monopoly and acquiring huge business benefits. Users not only fail to obtain data dividends, but also bear the risk of personal privacy being violated and personal data being abused.
The Next Generation Internet is a serverless Internet and a decentralized network. In this Internet, users have full ownership of their own data, and no one or any organization can use their data without permission. But it also brings the following problems:
- Any individual can only get hold of a small subset of the massive amount of data. It is impossible for any entity to stream the whole set of data valuable to them, handicapping their full grasp of the landscape. Every participant of the digitalized world is partially blind, blocked in a certain angle towards the full picture.
- Participants are weakly trusted or even untrusted, and they cannot use “trusted third parties” for data collection and validity verification, as well as the sharing of value, information and assets. Emerging cloud computing platforms are now typical “trusted third party”.
PlatON is committed to building the next generation of Privacy-Preserving Computing and data exchange network. Based on modern cryptography and blockchain technology, PlatON creates a new computing paradigm to maintain privacy of the client’s data without the need to rely on third parties for collaborative computing and verify the integrity of the results.


Scalable Privacy-Preserving Computing
Blockchain: Consensus-based Strategy
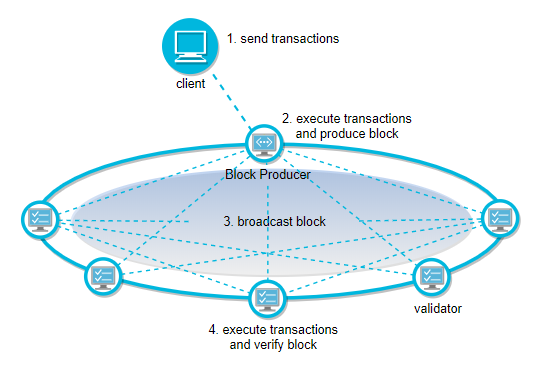
In a broad sense, the existing blockchain architecture is a consensus-based schemes, which also implements a simple computation protocol based on smart contract. To assure correctness the computation must be replicated by all the nodes, manifesting the intrinsic contradiction between efficiency and trustlessness.
Driven by practicality, the blockchain industry focuses on two issues: scalability and privacy.
Scalability is still a huge challenge for the blockchain. The mainstream blockchain is not highly-effective in processing transactions per second, which is several orders of magnitude different from the processing power required to run mainstream financial markets. Although there are hundreds of projects addressing scalability issues through various solutions which are limited to the “impossible triangle” at the expense of decentralization or security. In consensus-based schemes, smart contract is limited to support simple computing logic.
Privacy is another major issue of blockchain. Although the blockchain’s advantages such as immutability, decentralization, and no trust are tempting, it also faces the same dilemma of obtaining data as big data and AI technologies. Neither companies nor individuals have the willingness to share private information, or post to public ledges that will be freely read by governments, family, colleagues and business competitors without lockup.
PlatON: Non-interactive Proof Privacy-Preserving Computation
PlatON uses modern cryptographic algorithms including but not limited Zero-Knowledge Proof (ZKP), Verifiable Computation (VC), Homomorphic Encryption (HE), Secure Multi-Party Computation (MPC), Secret Sharing (SS), etc. to implement non-interactive proof computation scale solution.
Scalability
The scalability problem of the existing blockchain architecture is mainly due to the tight coupling of consensus and computing. PlatON’s scheme based on verifiable computing uses cryptographic algorithms to weaken their endogenous binding relationship, thereby fundamentally decoupling consensus and computing.
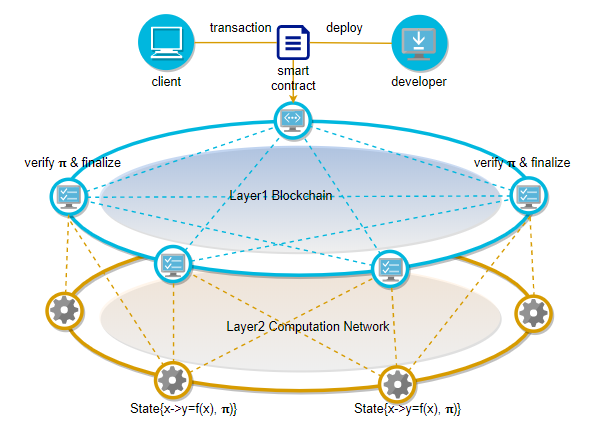
To avoid the trade off in efficiency, people in the industry have increasingly come to an agreement: the proper use of blockchain is for verification only; the computing tasks must be separated from the consensus layer and migrated off-chain, but the untrusted off-chain is new problem. PlatON’s Verifiable Computation (VC) cryptographic algorithm passes trust off-chain. Through verifiable computation, the contract only needs to be processed off-chain once, and all nodes can quickly verify the correctness.On the one hand, it improves the transaction processing performance, and on the other hand, it makes PlatON support complex contracts.
Privacy
On PlatON, MPC and HE are combined to achieve complete privacy-preserving computing, ensuring the privacy of input data and the computation logic. Compared to trusted computing that relies on the trusted hardware or TEE (such as SGX) provided by a third-party manufacturer for computational integrity, trustless computing on PlatON relies only on falsifiable cryptographic assumptions, and thus during its life, it provides unprecedented private data security without trust boundaries.
PlatON Overall Architecture
Overall Logical Structure
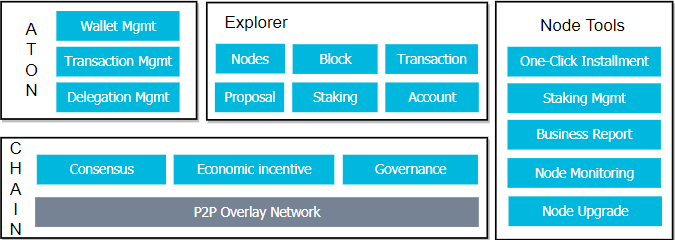
In addition to providing the underlying chain, PlatON also provides open source implementations of a wallet, a block browser, and a node management tool:
- ATON Wallet – A mobile wallet that supports hot and cold wallet, transaction and delegation. The private key is managed on the client, and Keyshared (a key management system based on threshold signature) is subsequently supported.
- PlatScan Block Browser – The official block browser provided by PlatON
- Node Tool
Logical Structure

PlatON’s Layer1 consensus network layer is based on the Ethereum skeleton. The core components have been completely rewritten, and some new components have been extended:
- Cryptographic algorithm: In addition to the SHA256Hash algorithm and ECDSA signature algorithm that have been used since Bitcoin, PlatON also adds BLS as aggregate signature for consensus, VRF for random election of validators, and ZKP and HE for privacy preserving.
- P2P network: Instead of using the popular libp2p and devp2p libraries, PlatON implements RELOAD (REsource LOcation And Discovery) protocol defined by RFC6940 and ReDiR(Recursive Distributed Rendezvous) service discovery mechanism defined by RFC7374.
- Account model and data storage: Following Ethereum’s account model, state data is stored in the Patricia tree. Due to the large amount of data, PPoS-related data is stored in the Patricia tree with poor performance. It is not stored in the Patricia tree, but is stored separately in another SNAPDB that does not store historical status.
- Consensus mechanism: use BFT-style PoS consensus mechanism. PPoS is a DPoS mechanism with VRF. The randomness introduced by VRF can endogenously curb the expansion of staking pools and ensure the decentralization and security. PlatON’s CBFT consensus mechanism is a three-phase pipelining consensus protocol that and produce and verifies batch blocks in parallel, thereby improves the consensus efficiency.
- Smart contract: Support EVM and WASM virtual machine at the same time, and support mainstream programming languages such as Solidity, C ++, Java, Python. A modified version of Truffle is provided to support the development of Solidity and C ++ contracts.
- DAPP SDK: Based on Ethereum’s WEB3 (supports Javascript, Java, Python, Swift languages) and JSON RPC, it is modified according to the function of PlatON. In addition, a more efficient GRPC-based interface has been added.
Layer2 extends complex computing to off-chain and implements Privacy-Preserving Computing protocols through off-chain Secure Multi-Party Computation.
- Cryptographic algorithm: Verifiable Computation (VC) algorithm can implement the non-interactive proof of off-chain computing scale solution. The privacy computing protocol is implemented by combining Secure Multi-Party Computation (MPC), secret sharing (SS), and homomorphic encryption (HE).
- MPC virtual machine: The privacy contract is compiled into the LLVM IR and executed in the MPC VM implemented through the LLVM JIT. The privacy calculation protocols including MPC, SS, and HE have been built into the MPC VM to reduce the size of the LLVM IR compiled from the privacy contract.
- Computing specific hardware: Computing specific hardware based on FPGA/ASIC can greatly improve computing performance and reduce computing power.
- Privacy computing and data exchange protocol: A computing protocol that enables collaborative computing and results verification without revealing the original data.
- Privacy-Preserving Computing Framework: A development framework that encapsulates Privacy-Preserving Computing and data exchange protocols, including a privacy AI development framework based on a Privacy-Preserving Computing protocol.
Network Structure
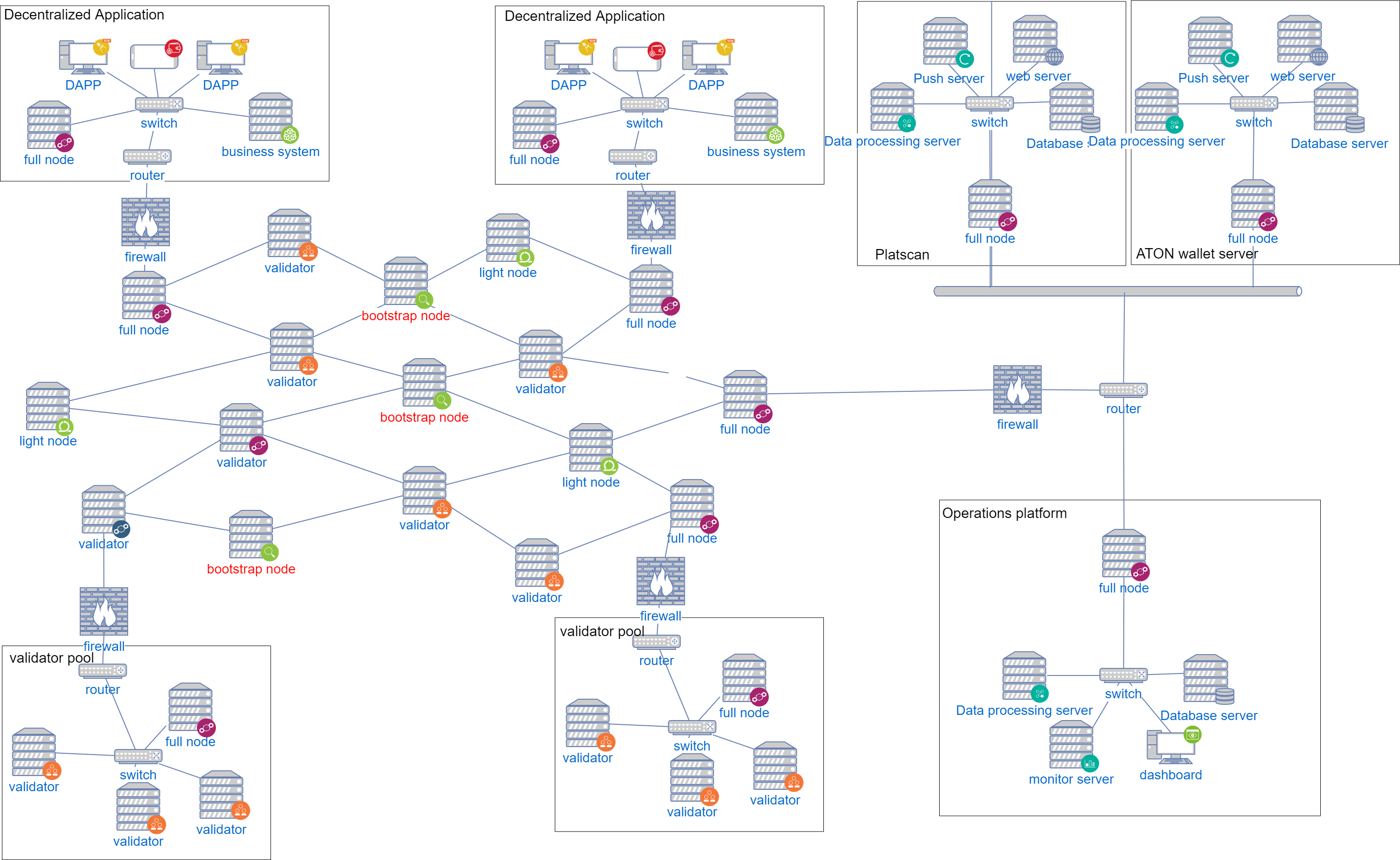
Basic Network
PlatON’s basic blockchain network is mainly composed of the following types of nodes, which are connected by P2P:
In general, we can divide node into two types: full nodes and light(weight) nodes. Full nodes verify block that is broadcast onto the network. Full nodes that preserve the entire history of transactions are known as full archiving nodes.Light nodes, in contrast, do not verify every block or transaction and may not have a copy of the current blockchain state. They rely on full nodes to provide them with missing details.
- Light Nodes Light nodes do not verify every block or transaction and may not have a copy of the current blockchain state. They rely on full nodes to provide them with missing details.
- Full Nodes Full nodes verify block that is broadcast onto the network. That is, they ensure that the transactions contained in the blocks (and the blocks themselves) follow the rules defined in the PlatON specifications. All full nodes will have to replay all the transactions to ensure that they arrive at the correct, agreed-upon next state of the blockchain.
- Archive Nodes Full nodes that preserve the entire history of transactions are known as full archiving nodes.
- Bootstrap Nodes The new node joins the PlatON network and first connects to the bootstrap node and discovers other nodes.
- Validator Nodes Responsible for production and verify blocks, validator nodes are randomly selected through PPoS + VRF, and run the CBFT protocol for consensus.
Decentralized Application
To deploy DAPP applications (including blockchain), the following servers need to be deployed in the intranet environment:
- Full node This node must connect to mainnet or testnet of PlatON. The P2P port of the node can be exposed to the internet, but the RPC port is not recommended to be exposed to the internet.
- DAPP server The DAPP server is connected to the local full-node RPC port, monitor transactions, events, and blocks on the chain. At the same time, the DAPP server is also connected to the original business system of the enterprise.
Validator pool
The validator pool deploys multiple validator nodes, and it is recommended to connect to the internet through a public front-end full node. For specific security deployment solution, see validator deployment.
Operations platform
The Operations platform synchronizes all blocks, transactions, and events through a full node and perform monitoring.
PlatScan Block Browser
The PlatScan block browser synchronizes all blocks, transactions, and events through a full node, and displays data such as blocks and transactions. The PlatScan block browser requires the following servers to be deployed:
- Full node: RPC port allows only data processing server access
- Data processing server
- Database server
- WEB server
- Push server
ATON wallet server
ATON is a mobile wallet which implements key management, signing transactions forwarded to the chain through the ATON server. The data including transaction, block, validator on the chain are synchronized by the ATON server through the full node and pushed to the mobile client. ATON wallet server needs to deploy the following servers:
- Full node: RPC port allows only data processing server access
- Data processing server
- Database server
- WEB server
- Push server
Validator Deployment
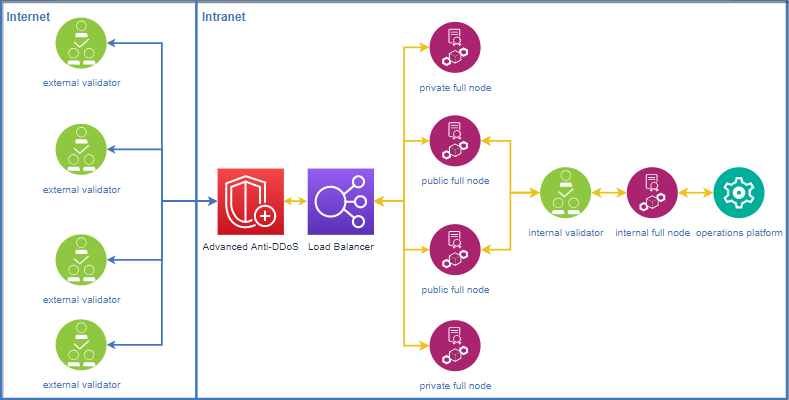
Appropriate measures should be taken to ensure the security of validator for running stably:
- RPC ports of full node and validator node are closed.
- The validator node is not exposed on the Internet and communicates through non-validator full nodes.
- Each validtor node should have at least 2 public full nodes and 2 non-public full nodes. The IPs of the public full nodes can be exposed on the Internet. The IPs of the non-public full nodes are only exposed to other reliable validator nodes and are not exposed on the Internet to avoid DDoS attacks.
- Prevent network-wide scanning to locate highly-defensive servers. Modify the port 9876 (the same as RPC 8888) to ports 80, 443, or 22. This can effectively increase the cost of attacker positioning.
Core Modules
P2P Network
The basic implementation of PlatON network is a decentralized structured topology completely based on RELOAD (Resource Location And Discovery) protocol and the Kademlia protocol [Kademlia]. The overall PlatON network structure is shown as follows.
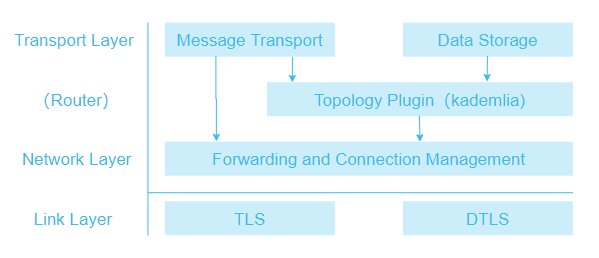
Link Layer
The Link Layer ensures the secure transfer of data. A variety of transmission protocols are employed to prevent eavesdropping, tampering and spoofing; to provide secure and authenticated connections; and to verify the source of messages and ensure the integrity of the data.
Transport Layer Security (TLS) and Datagram Transport Layer Security (DTLS) are implemented on this layer.
Forwarding and Connection Management
The Forwarding and Connection Management layer stores and implements the Routing Table by providing packet forwarding services between nodes. It also handles establishing new links between nodes, setting up connections for overlay links across NATs using ICE.
Topology Plug-in
RELOAD is a P2P network framework that supports the development of different topology algorithms for implementing a fully-distributed non-structured topological or fully-distributed structured topological network.
The Topology Plug-in is responsible for implementing the specific overlay algorithm being used. It uses the Message Transport component to send and receive overlay management messages, the Storage component to manage data replication, and the forwarding and connection management layer to control hop-by-hop message forwarding.
The Topology Plug-in allows RELOAD to support a variety of overlay algorithms. PlatON implements a DHT based on Kademlia algorithm.
Data Storage
The Data Storage Layer is responsible for processing messages relating to the storage and retrieval of data. It talks directly to the Topology Plug-in to manage data replication and migration, and it talks to the Message Transport component to send and receive messages.
The base RELOAD protocol currently defines three data models: single value, array and dictionary.
Message Transport
The Message Transport layer is responsible for handling end-to-end reliability.
PlatON uses RELOAD as the basis for developing a Regional Flooding algorithm that broadcasts messages quickly throughout the entire network.
Application Layer
The communication and storage capabilities of the RELOAD base layer are used to provide service discovery and scaling as well as routing, computing, data, storage and blockchain services based on service discovery.
Service Discovery
PlatON uses ReDiR (Recursive Distributed Rendezvous) [RFC7374] to implement the service discovery mechanism. ReDiR can support tens of thousands of service provider nodes and service query nodes.
ReDiR Tree
ReDiR uses a tree structure to implement the P2P service discovery mechanism. At the same time, the storage capacity of the RELOAD overlay network is used to save the data. Each type of service is stored as a ReDiR tree, and the tree nodes save the information of the service providing nodes. When a node requests to find a specified service provider, a limited number of searches in the ReDiR tree can find the service provider node that best matches the requesting node.
Each tree node in the ReDiR tree contains a dictionary of entries of peers providing a particular service. Each tree node in the ReDiR tree also belongs to some level in the tree. The root node of the ReDiR tree is located at level 0. The child nodes of the root nodes are located at level 1 of the ReDiR tree. The child nodes of the tree nodes at level 1 are located at level 2, and so forth.
The number of nodes in each layer of the ReDiR tree depends on the branching factor b. Each layer can hold up to blevel nodes. Each node is uniquely identified by (level,j), where levellevel is the node location.The number of layers, j means that the node is the jj node in the corresponding layer. In each layer, blevel tree nodes divide the level layer into blevel KEY spaces.
All services providers are mapped into corresponding key space. A tree node is responsible for the storage of each key space. Tree node contains key space

Service Registration
A node nn with key kk use the following procedure to register as a service provider in the RELOAD Overlay Instance:
- Step 1: Starting at some level l=lstart. This is generally 2.
- Step 2: Node n sends a RELOAD Fetch request to fetch the contents of the tree node responsible for key space I(l,k).and obtains the list of service nodes that the tree node stores.
- Step 3: Node n sends a RELOAD Store request add its entry to the dictionary stored in the tree node responsible for key space I(l,k).
- Step 4: If node n’s key is the lowest or highest key stored in the tree node responsible for key space, node n MUST reduce the current level by one, repeating steps 2 and 3 above. Node n continue in this way until it reaches either the root of the tree or a level at which k is not the lowest or highest key in the key space.
In the same way, node nn also performs a downward walk from level l=lstart recursively until the following condition is satisfied:node nn is the only service provider in the tree node responsible for key space I(l,k).
Service Refresh
All state in the ReDiR tree is soft. Therefore, a service provider needs to periodically repeat the registration process to refresh its Resource Record. If a record expires, it must be dropped from the dictionary by the peer storing the tree node.
Service Lookup
A service lookup is similar to service registration. It also starts from an initial layer l=lstart. At each step gets the list of service nodes in the current KEY space I(l,k), and it is processed as follows:
- Step 1: If there is no service provider stored in the tree node associated with, then service provider corresponding to KEY(k) must occur in a larger range of the keyspace, so we decrease the number of layers by 1 and repeat the query, or fail if level is equal to 0.
- Step 2: If k is sandwiched between two client entries in, then the service provider must lie somewhere in a sub-space of . We set and repeat.
- Step 3: Otherwise, the returned result must be the service provider closest to key(k) and the lookup is done.
Account Model
Compared with the account model, UTXO does not support smart contracts, and many DAG projects are actively exploring smart contracts, but there is no mature and stable solution. Therefore, PlatON chooses mature and stable account models that support smart contracts. In PlatON, each account has a state associated with it and a 20-byte address. There are two types of accounts:
- Ordinary account
Controlled by the private key, users can generate it through the wallet client or the command line. In PlatON, ordinary accounts can create transactions and use private keys to sign transactions.
- Contract account
There is no private key, it is controlled by code, and the contract account address is generated when the contract is deployed. Unlike ordinary accounts, contract accounts cannot initiate new transactions on their own. Whenever a contract account receives a message, the code inside the contract is activated, allowing it to read and write to internal storage, and send other messages or create a contract.
Data Storage
In the original bitcoin blockchain, only ordinary transfer transactions need to be stored. Bitcoin is based on the UTXO model, which means that all the information stored on the chain is UTXO except for block-related information (hash, nonce, etc.) Smart contracts are generally supported in the blockchain 2.0 public chain represented by Ethereum. The content stored in the contract can be arbitrary. In addition to account-related information (such as tokens), users can also send text and pictures , videos, and so on.
In some chains (such as Ethereum), in order to ensure data integrity, some state data (or historical data) is usually stored on the chain. These data are only useful in the corresponding block (height), and there is no other height. It is useful. The advantage of doing this is that at any time, I can trace what the full picture of the ledger looks like at a certain height in history, but the disadvantages are also obvious: the cost of storage is high. Therefore, there is a public chain storage solution similar to EOS. In addition to storing only the latest status data, EOS also uses the star file system to share the pressure on storage.
PlatON believes that on-chain storage requires full consideration of costs. Only valuable information that requires consensus among all ledgers should be stored on the public ledger. Valuable information includes: blocks, transactions, and account data. For some information in the economic model, such as the validator list of the current consensus round, the candidate list, and the current block rate of each node, it is only necessary to store the latest data.
PlatON’s storage is divided into account data storage (statedb) and snapshot storage (snapshotdb).
Account data storage (statedb)
PlatON’s account data storage references Ethereum’s MPT tree storage model, as shown below:
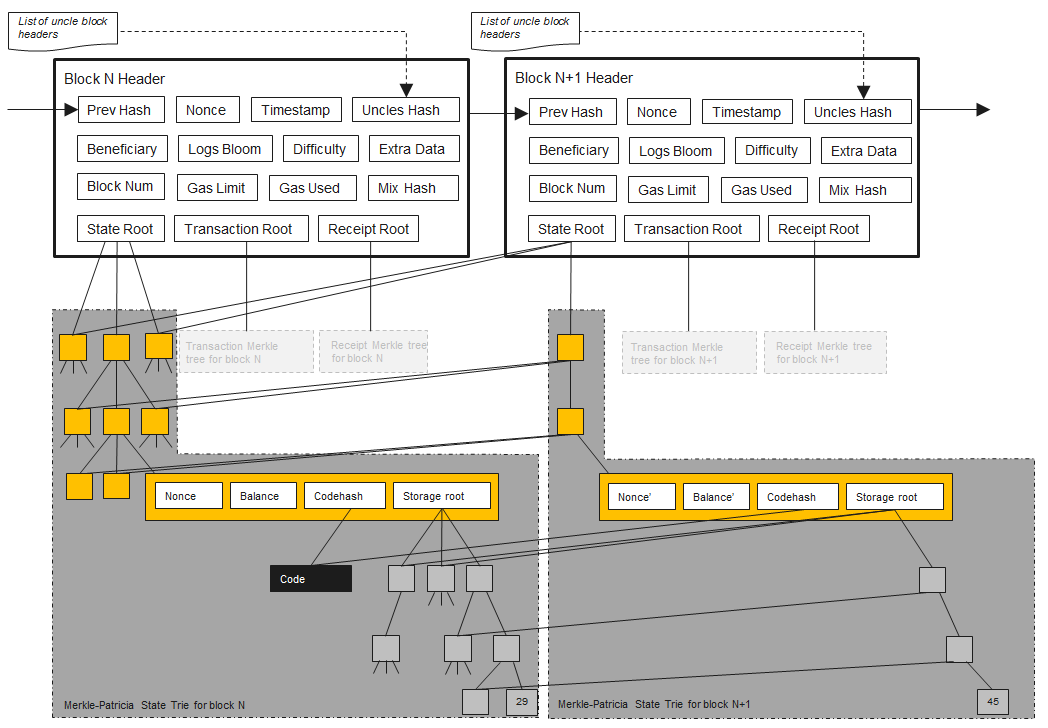
In PlatON, all account-related state information is stored and retrieved through StateDB. To support fast data query and block rollback operations, StateDB uses the MPT structure as its underlying storage method. All nodes in the MPT will eventually be stored in the disk database as key-value.
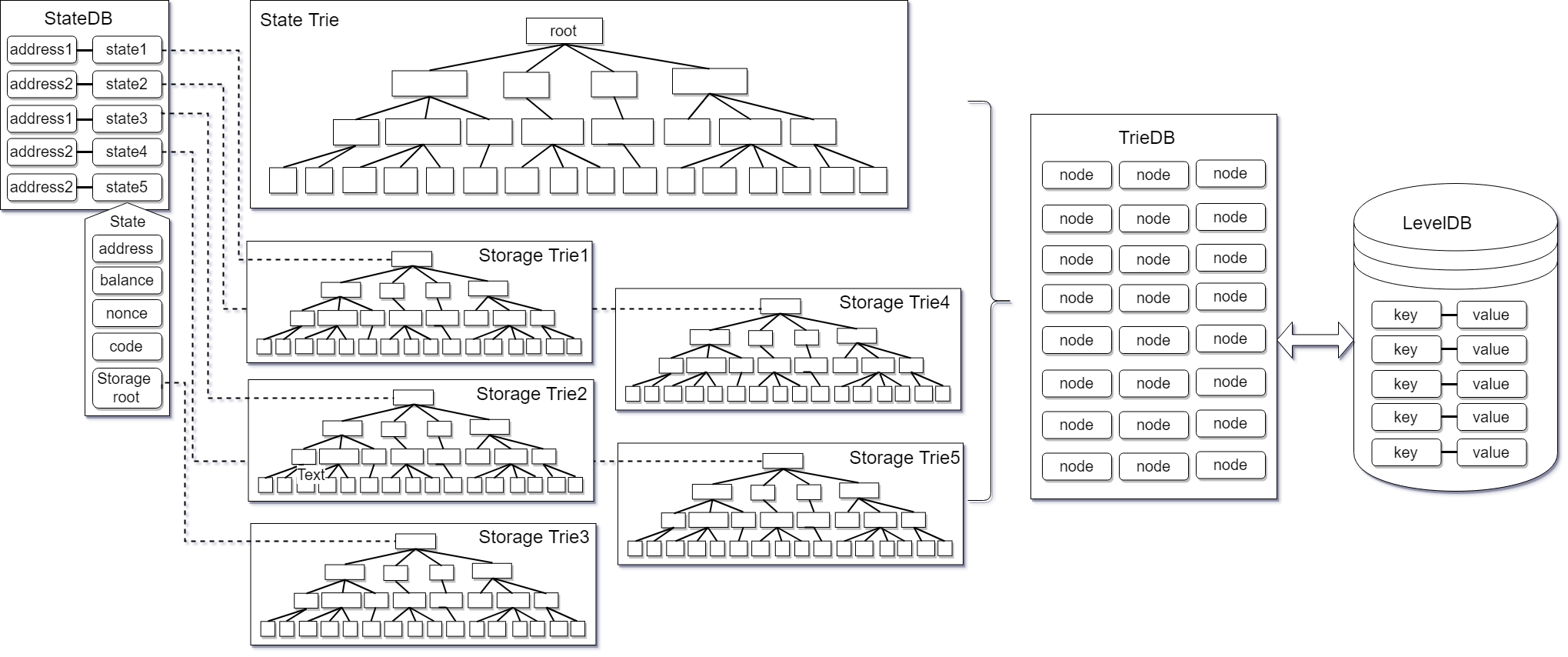
The top layer is StateDB. StateDB is responsible for making the most preliminary records of the data. The next layer is the Trie layer. Trie is responsible for structuring all data and subsequent operations such as rollback of storage queries. There are two types of Trie, State Trie and Storage Trie. The former is a status tree that records basic information such as the balance nonce of all accounts. The latter is used to record various contract storage data. There is only one state tree and many storage trees, because each contract has its own storage tree. Trie is TrieDB. TrieDB stores the order of the nodes in Trie in memory. TrieDB’s main function is to act as a cache layer before finally inserting data into the hard disk. The last link in the entire structure is the database leveldb on the final hard disk.
Snapshot Data Storage (snapshotdb)
Considering storage cost and read performance, part of the data in PlatON only retains the final state, which is stored and retrieved through snapshotdb. The data in snapshotdb will be finally stored in the disk database in the form of key-value.
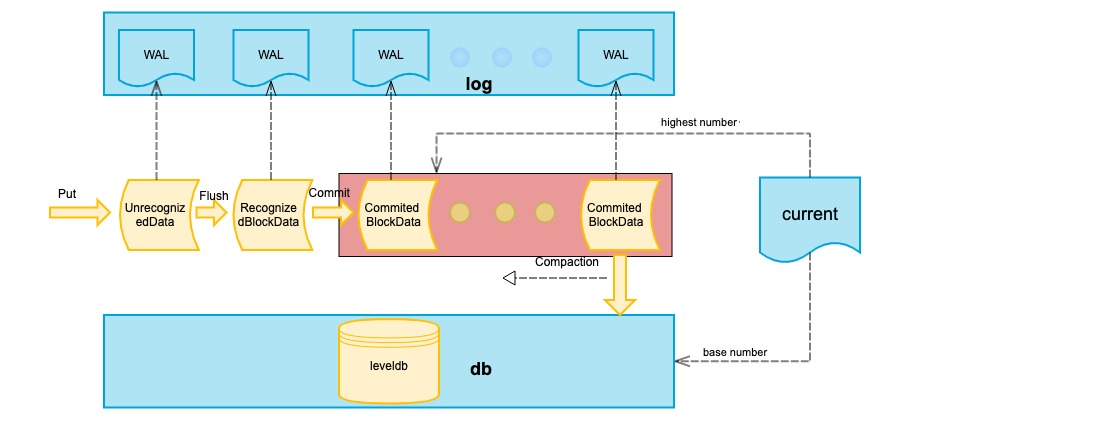
among them:
- unRecognizedBlockData: An unconfirmed data set. Each DB write request updates the data set.
- RecognizedBlockData: Confirmed block data. BlockData will become RecognizedBlockData after Flush. RecognizedBlockData has a corresponding relationship with block hash and number. There can be multiple RecognizedBlockData for the same block height. After committing, delete the same block height and the following other RecognizedBlockData.
- CommitedBlockData: Block data waiting for Compaction, there is only one path (block association).
- WAL: log file, write log before all data is recorded. Store k, v, hash data, hash = hash (k + v + hash)
- current: is used to store the height of the current highest commit block and the highest merge block (base) block
Consensus mechanism
The scalability trilemma posits that blockchains in which every node processes every computation and in which every node comes to consensus about the order of those computations can have two of three properties: safety, scalability, and decentralization of block production.
- The decentralization of block production can be quantified as the number of block producers.
- Scalability can be quantified as the number of transactions per unit of time that the system can process.
- Safety can be quantified as the cost of mounting a Byzantine attack that affects liveness or transaction ordering.
As a trade-off, PlatON uses a BFT-Style PoS mechanism.
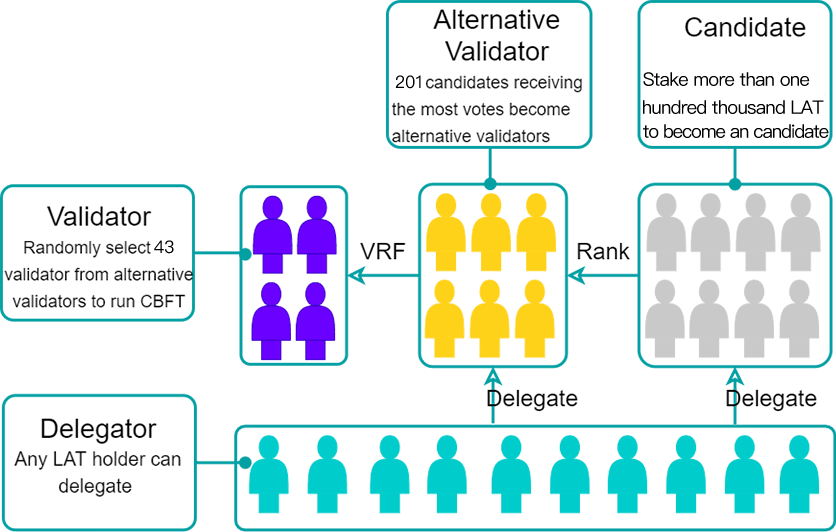
PlatON consensus runs in three stages:
- Phase 1: The Election of Alternative Validators;
In PlatON, every LAT holder can participate in PPoS.
For an LAT holder who wants to become a validator, he/she must stakes more than a pre-specified minimum number of LATs to first become an alternative validator candidate. One staked LAT means one vote, which must be voted for himself and no one else. In other words, alternative validator candidates aren’t allowed to vote for each other.
Other LAT holders who want to participate in the election of alternative validators must stake LATs too. The number of LATs locked against them must be greater than or equal to 10 LATs. They can vote for any alternative validator candidates they choose.
After all the votes are cast, alternative validator candidates are ranked according to how many votes they received. A pre-specified number of candidates receiving the most votes become alternative validators. The LATs staked by alternative validators and their supporters remain staked until the end of a pre-specified lock-up period. For other candidates and their supporters, their staked LATs can be un-staked immediately after the election. They won’t participate in current round of PPoS anymore and won’t get any compensation, either.
- Phase 2: The Selection of Validators by the VRF
The VRF is used to select a pre-specified number of validators within all the alternative validators. The details of the VRF are very complicated. But it is equivalent to the following experiment.
Firstly, imagine every vote received by each alternative validator as a ball. Mark different alternative validators by different colors, and mix all the balls together. Secondly, randomly draw a ball from the pool, record its color, and put it back. Repeat this step for many times. Thirdly, count the color distribution of the balls drawn from the pool. Those alternative validators corresponding to the colors with the most occurrences become validators.
It can be proved that the more votes an alternative validator receives, the more likely it will be selected by the VRF as a validator. However, the VRF introduces a considerable level of randomness. The validators selected may not correspond to the alternative validators with the most votes.
- Phase 3: Validators Run CBFT
In CBFT, every validator is assigned a time window, during which it produces a pre-specified number of blocks consecutively. All the validators then run CBFT to reach consensus on the candidate blocks.
After receiving block reward and staking reward, validators and alternative validators share their income with supporters according to agreements between them. Validators’ income also includes transaction fees.
Smart contract
From a technical perspective, PlatON is essentially a decentralized FaaS (Functions as a Service) platform. Accordingly, smart contracts can be considered as functions on FaaS. Smart contracts in PlatON fall into three categories.
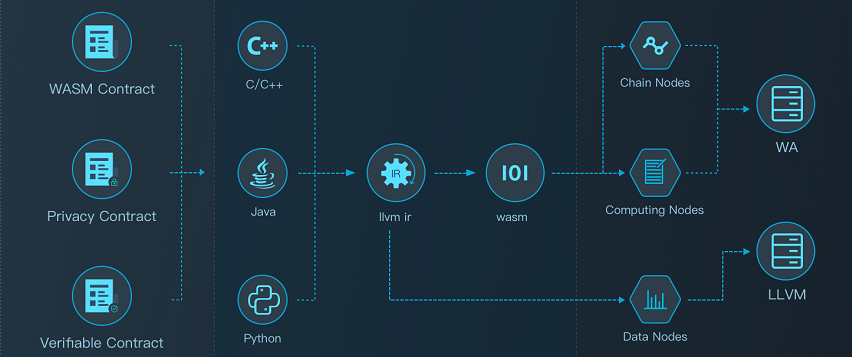
Solidity Contract
Solidity contract Supports development using solidity language, compiled into evm bytecode for execution. The transactions that trigger the solidity contract are packaged by validators, and nodes across the network repeatedly perform verification. The status of solidity contracts is kept in the statedb.
WASM Contract
Wasm contract Supports high-level language development, compiled into WASM bytecode for execution. The transactions that trigger the Wasm contract are packaged by validators, and nodes across the network repeatedly perform verification. The status of the Wasm contract is kept in the statedb.
WASM Virtual Machine
PlatON uses wagon as the PlatON virtual machine. As a PlatON virtual machine, it needs to be transformed. To implement external functions on the chain and how GAS is calculated.
Toolchain
PlatON first supports C ++ as a smart contract writing language, and gradually provides mainstream high-level development languages such as Rust and Go. The following tool chains are provided for C ++:
- platon-cpp: C ++ compiler, responsible for generating WASM object code and ABI files.
WASM contract execution process
GAS Billing for WASM Contracts
The execution of the WASM contract is performed in accordance with the called WASM instruction for GAS billing. Different WASM instructions have different GAS. The GAS value of the specific WASM instruction is supplemented later.
Privacy Contract
Privacy contract scheme
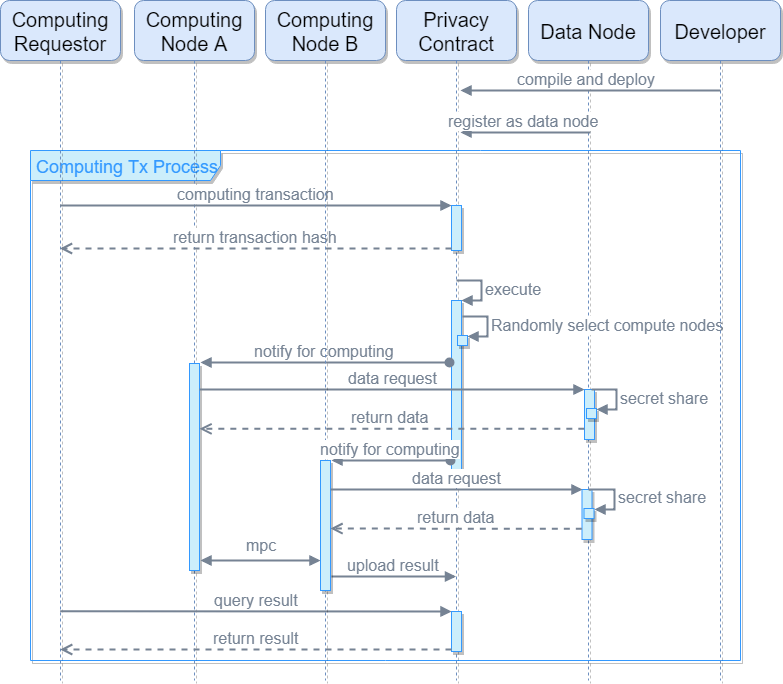
The privacy contract also supports high-level language development, which is compiled into llvm ir intermediate language for execution. The input data of the privacy contract is stored locally in the data node, and the data node is secretly shared to multiple random computing nodes. The computing node performs privacy computations in a secure multi-party computing manner off-chain, and submits the computation results to the chain.
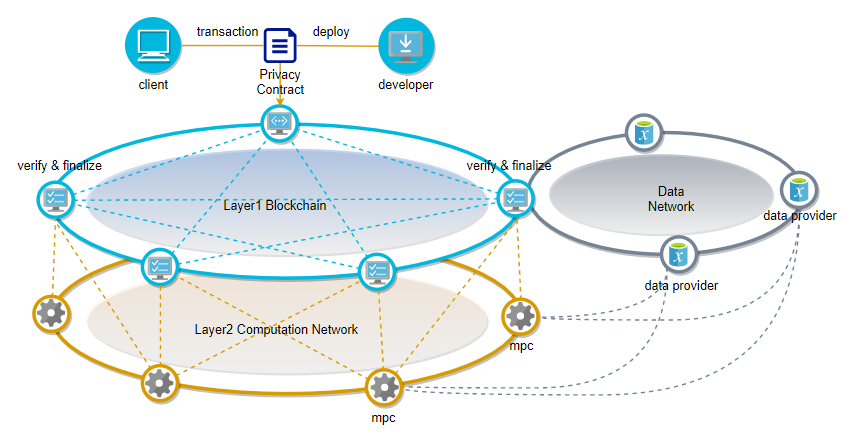
Privacy contract execution process
VC Contract
The development and release of a verifiable contract is no different from a Wasm contract, and it is eventually compiled into a WASM implementation. The state transition of the verifiable contract is performed asynchronously by the computing nodes off-chain. After the computation is completed, new states and state transition certificates are submitted to the chain. The nodes on the entire network can quickly verify the correctness and update the new state to the public ledger. Verifiable contracts can support complex and heavy computation logic without affecting the performance of the entire chain.
Verifiable contract scheme
PlatON’s verifiable solution is temporarily based on the zk-SNARK algorithm, and it is gradually replaced with a more optimized algorithm in the future.

- vc-contract template: The user compiles a vc contract according to the provided template, and can enter any computation model. It mainly implements three interfaces:
- compute (): compute request
- real_compute (): Generate computation results and proofs
- set_result (): verify computation result and proof
- vclang: compile the vc contract written by the user to generate an executable file supported by WASM vm. Contract developers do not need to care about the specific use of libsnark api, they only need to write their own computation model code.
- vcc-reslover: built-in interface layer to support access to libcsnark in WASM virtual machine, calling libcsnark interface in c-go mode
- libcsnark: encapsulates the libsnark api, libsnark implemented by c ++ can be accessed by the c interface
- vc_pool: responsible for vc’s transaction processing, distributing vc computation tasks, and uploading the computation results and proofs to the chain
Verifiable contract execution process
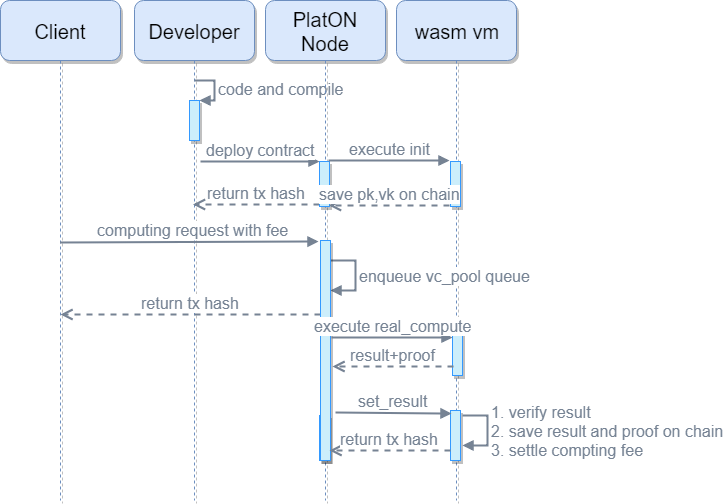
- After the contract is compiled, pk and vk have been generated. After deployment to the PlatON network, pk and vk are stored on the chain and cannot be tampered with, which can facilitate node access
- When the vc compute transaction is executed, a vc task is created, taskid is composed of the nonce of tx, and taskid is the key to store the input parameter x
- After the compute transaction is written into the block, it will trigger the vc_pool to resolve the transaction event, so as to decide whether to add the task to the vc_pool queue
- After the block is confirmed, real_compute can be executed. Because it is off-chain computation, no transaction fees will be incurred. The process of real_compute is to first generate s (witness) according to the gadget sequence operation that was previously compiled and generated. Once s is calculated, you can calculate the proof based on pk
- set_result (proof, result) is to upload the computation result and proof to the chain. This process is mainly verify (vk, proof, input). Once the verification is passed, the transaction initiator can get the computation reward. The verification time of zk-SNARK is relatively short compared to the stage of generating proof, but it is also related to the length of the input parameter. Therefore, it is necessary to pay attention to limit the length of the input parameter to prevent the gas cost of the transaction from being too high and increase the cost of the verifier.
Incentive model
Users who need computing outsourcing need to mortgage the appropriate fees to the contract account first, and each computing node can compete for the computing task by itself (the order-changing model will be changed to the random ordering model later). Once the computation is successful, the result and proof are generated, and set_result is initiated. For a transaction request, the computing node needs to pay the miner fee for the transaction first. The node receives the request and executes set_result. Once the proof and result parameters carried in the transaction are verified, the transaction requester successfully calculates the result and the contract account will be mortgaged. Fees are transferred to the requester’s account, failure will not be rewarded.
This article is reproduced from https://devdocs.platon.network/docs/en/PlatON_Overall_Solution/#validator-deployment



